Hive任務執行慢但是導入數據非常的快是為什么
這篇文章主要講解了“Hive任務執行慢但是導入數據非常的快是為什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Hive任務執行慢但是導入數據非常的快是為什么”吧!
站在用戶的角度思考問題,與客戶深入溝通,找到龍安網站設計與龍安網站推廣的解決方案,憑借多年的經驗,讓設計與互聯網技術結合,創造個性化、用戶體驗好的作品,建站類型包括:做網站、成都做網站、企業官網、英文網站、手機端網站、網站推廣、域名注冊、網頁空間、企業郵箱。業務覆蓋龍安地區。
讀時模式和寫時模式
Hive使用Hadoop來執行查詢,其查詢執行速度是很慢的,但是使用load data向Hive中導入數據卻非常快,這是因為Hive采取的是讀時模式(Schema On Read)。
讀時模式:讀取數據的時候,對數據的類型、格式做檢查;
寫時模式:寫入數據的時候,對數據的類型、格式等規范做檢查;
將數據存到Hive的數據表時,Hive采用的是“讀時模式”,意思是針對寫操作不會做任何校驗,只是簡單的將文件復制到Hive的表對應的HDFS目錄。跟“讀時模式”相對應的是“寫時模式”,RDBMS一般采用“寫時模式”,在將數據寫入到數據表的時候會檢查每一條記錄是否合法,如果檢查不通過會直接返回失敗信息。
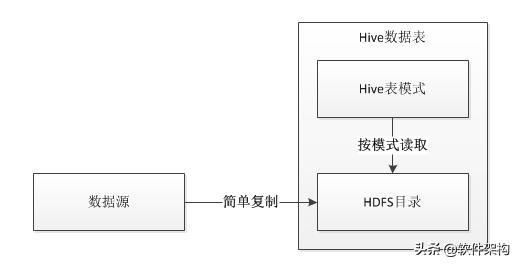
由于向Hive中存入數據的只是簡單的文件復制和粘貼,所以導入數據速度非常的快。當讀取、查詢的時候,才會根據表模式來解釋數據,這個時候如果遇到了不符合模式的數據,Hive會直接將數據解析成NULL。
讀時模式的好處
Hive采用讀時模式帶來了以下幾個好處:
向Hive表中新增數據非常的快,通常情況下對于外來數據,采用的方法是直接用Hadoop命令將文件上傳到一個HDFS目錄,Hive直接讀這個目錄;
一份數據可以被解析成多種模式,存儲在Hive表中的數據跟Hive本身沒有關系,數據也可以被其他工具比如Pig來處理;
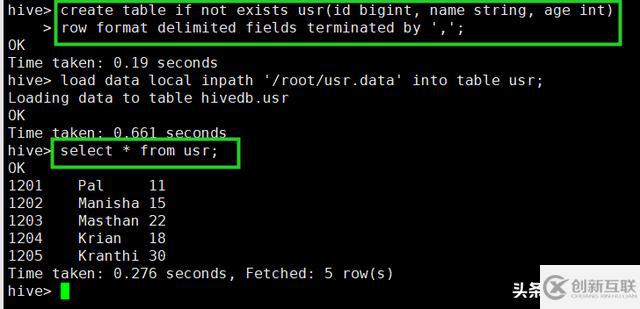
導入數據
hive> load data local inpath '/root/usr.data' into table usr;
感謝各位的閱讀,以上就是“Hive任務執行慢但是導入數據非常的快是為什么”的內容了,經過本文的學習后,相信大家對Hive任務執行慢但是導入數據非常的快是為什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是創新互聯,小編將為大家推送更多相關知識點的文章,歡迎關注!
當前標題:Hive任務執行慢但是導入數據非常的快是為什么
網頁鏈接:http://m.newbst.com/article12/gpjigc.html
成都網站建設公司_創新互聯,為您提供定制網站、動態網站、Google、App設計、網站建設、網站設計
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 淺談企業手機成都網站建設何做好內容建設 2015-04-03
- 成都電腦版網站和手機版網站如何訪問 2016-10-26
- 手機建網站,手機網站建設的幾點注意事項 2016-08-14
- 智能手機已經普及,但是為什么做手機網站的企業很少呢? 2016-11-12
- 手機網頁界面設計的方法 2016-11-14
- 手機網站建設需要具備哪些功能? 2023-04-17
- 成都專業網站建設公司首選手機網站建設成敗不只關乎錢的因素 2021-11-27
- 成都婚慶類手機網站建設注意事項 2016-09-22
- 手機網站建設應該如何解決網頁內的鏈接問題 2016-11-07
- 響應式網站建設對手機優化的好處 2016-06-08
- 手機網站建設的好處和發展前景 2013-07-09
- 「網站建設」手機端網站建設的有關關鍵點基本建設 2016-04-15