刨根問底Kafka,面試過程真好使-創(chuàng)新互聯(lián)
大家好,這里是 菜農(nóng)曰,歡迎來到我的頻道。

充滿寒氣的互聯(lián)網(wǎng)如何在面試中脫穎而出,平時積累很重要,八股文更不能少!下面帶來的這篇 Kafka 問答希望能夠在你的 offer 上增添一把🔥。
Kafka最初是由Linkedin公司開發(fā)的,是一個分布式的、可擴(kuò)展的、容錯的、支持分區(qū)的(Partition)、多副本的(replica)、基于Zookeeper框架的發(fā)布-訂閱消息系統(tǒng),Kafka適合離線和在線消息消費(fèi)。它是分布式應(yīng)用系統(tǒng)中的重要組件之一,也被廣泛應(yīng)用于大數(shù)據(jù)處理。Kafka是用Scala語言開發(fā),它的Java版本稱為Jafka。Linkedin于2010年將該系統(tǒng)貢獻(xiàn)給了Apache基金會并成為頂級開源項目之一。
Kafka 是個大家伙,本篇將通過40道問答作為路線,由淺入深,大程度上覆蓋整個 Kafka 的問答內(nèi)容(預(yù)習(xí)+復(fù)習(xí)一步到位)

1、Kafka 的設(shè)計
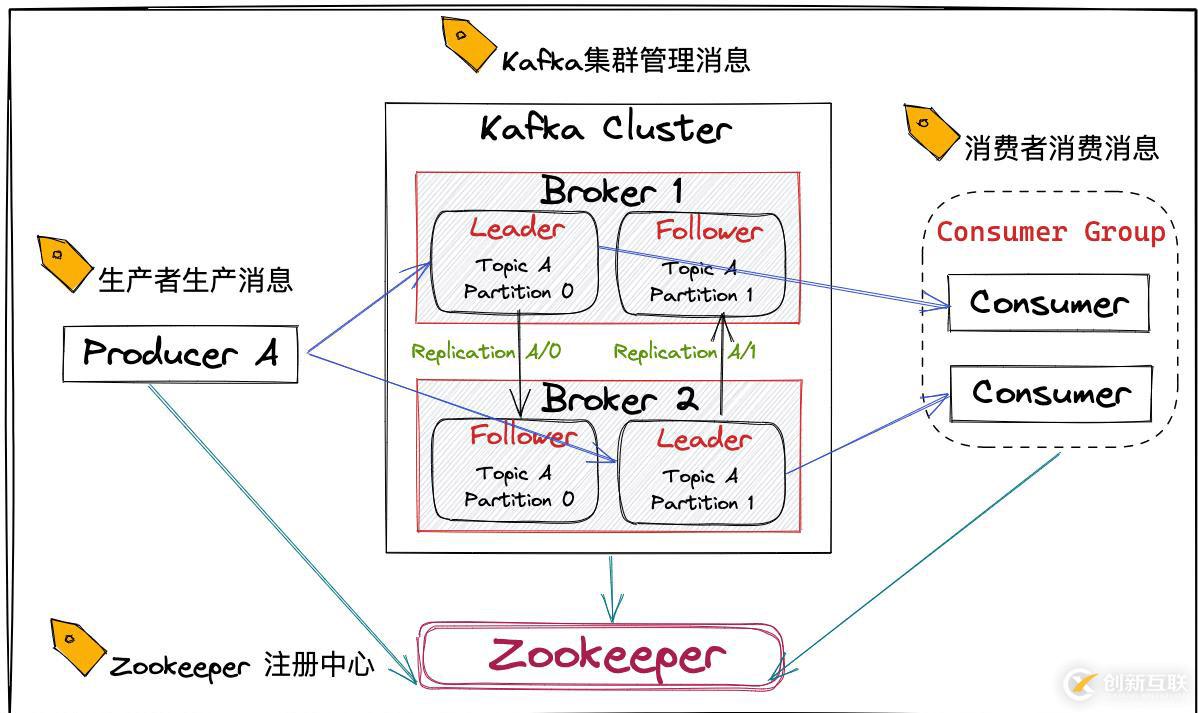
Kafka 將消息以 topic 為單位進(jìn)行歸納,發(fā)布消息的程序稱為 Producer,消費(fèi)消息的程序稱為 Consumer。它是以集群的方式運(yùn)行,可以由一個或多個服務(wù)組成,每個服務(wù)叫做一個 Broker,Producer 通過網(wǎng)絡(luò)將消息發(fā)送到 kafka 集群,集群向消費(fèi)者提供消息,broker 在中間起到一個代理保存消息的中轉(zhuǎn)站。
Kafka 中重要的組件
1)Producer: 消息生產(chǎn)者,發(fā)布消息到Kafka集群的終端或服務(wù)
2)Broker:一個 Kafka 節(jié)點(diǎn)就是一個 Broker,多個Broker可組成一個Kafka 集群。
如果某個 Topic 下有 n 個Partition 且集群有 n 個Broker,那么每個 Broker會存儲該 Topic 下的一個 Partition
如果某個 Topic 下有 n 個Partition 且集群中有 m+n 個Broker,那么只有 n 個Broker會存儲該Topic下的一個 Partition
如果某個 Topic 下有 n 個Partition 且集群中的Broker數(shù)量小于 n,那么一個 Broker 會存儲該 Topic 下的一個或多個 Partition,這種情況盡量避免,會導(dǎo)致集群數(shù)據(jù)不均衡
3)Topic:消息主題,每條發(fā)布到Kafka集群的消息都會歸集于此,Kafka是面向Topic 的
4)Partition:Partition 是Topic在物理上的分區(qū),一個Topic可以分為多個Partition,每個Partition是一個有序的不可變的記錄序列。單一主題中的分區(qū)有序,但無法保證主題中所有分區(qū)的消息有序。
5)Consumer:從Kafka集群中消費(fèi)消息的終端或服務(wù)
6)Consumer Group:每個Consumer都屬于一個Consumer Group,每條消息只能被Consumer Group中的一個Consumer消費(fèi),但可以被多個Consumer Group消費(fèi)。
7)Replica:Partition 的副本,用來保障Partition的高可用性。
8)Controller:Kafka 集群中的其中一個服務(wù)器,用來進(jìn)行Leader election以及各種 Failover 操作。
9)Zookeeper:Kafka 通過Zookeeper來存儲集群中的 meta 消息
2、Kafka 性能高原因- 利用了 PageCache 緩存
- 磁盤順序?qū)?/li>
- 零拷貝技術(shù)
- pull 拉模式
- Kafka把Topic中一個Partition大文件分成多個小文件段,通過多個小文件段,就容易定期清除或刪除已經(jīng)消費(fèi)完成的文件,減少磁盤占用
- 通過索引信息可以快速定位Message和確定response的大大小
- 通過將索引元數(shù)據(jù)全部映射到 memory,可以避免 Segment 文件的磁盤I/O操作
- 通過索引文件稀疏存儲,可以大幅降低索引文件元數(shù)據(jù)占用空間大小
優(yōu)點(diǎn)
- 高性能、高吞吐量、低延遲:Kafka 生產(chǎn)和消費(fèi)消息的速度都達(dá)到每秒10萬級
- 高可用:所有消息持久化存儲到磁盤,并支持?jǐn)?shù)據(jù)備份防止數(shù)據(jù)丟失
- 高并發(fā):支持?jǐn)?shù)千個客戶端同時讀寫
- 容錯性:允許集群中節(jié)點(diǎn)失敗(若副本數(shù)量為n,則允許 n-1 個節(jié)點(diǎn)失敗)
- 高擴(kuò)展性:Kafka 集群支持熱伸縮,無須停機(jī)
缺點(diǎn)
- 沒有完整的監(jiān)控工具集
- 不支持通配符主題選擇
- 日志聚合:可收集各種服務(wù)的日志寫入kafka的消息隊列進(jìn)行存儲
- 消息系統(tǒng):廣泛用于消息中間件
- 系統(tǒng)解耦:在重要操作完成后,發(fā)送消息,由別的服務(wù)系統(tǒng)來完成其他操作
- 流量削峰:一般用于秒殺或搶購活動中,來緩沖網(wǎng)站短時間內(nèi)高流量帶來的壓力
- 異步處理:通過異步處理機(jī)制,可以把一個消息放入隊列中,但不立即處理它,在需要的時候在進(jìn)行處理
主題是一個邏輯上的概念,還可以細(xì)分為多個分區(qū),一個分區(qū)只屬于單個主題,很多時候也會把分區(qū)稱為主題分區(qū)(Topic-Partition)。同一主題下的不同分區(qū)包含的消息是不同的,分區(qū)在存儲層面可以看做一個可追加的日志文件,消息在被追加到分區(qū)日志文件的時候都會分配一個特定的偏移量(offset)。offset 是消息在分區(qū)中的唯一標(biāo)識,kafka 通過它來保證消息在分區(qū)內(nèi)的順序性,不過 offset 并不跨越分區(qū),也就是說,kafka保證的是分區(qū)有序而不是主題有序。
在分區(qū)中又引入了多副本(replica)的概念,通過增加副本數(shù)量可以提高容災(zāi)能力。同一分區(qū)的不同副本中保存的是相同的消息。副本之間是一主多從的關(guān)系,其中主副本負(fù)責(zé)讀寫,從副本只負(fù)責(zé)消息同步。副本處于不同的 broker 中,當(dāng)主副本出現(xiàn)異常,便會在從副本中提升一個為主副本。
7、Kafka 中分區(qū)的原則- 指明Partition的情況下,直接將指明的值作為Partition值
- 沒有指明Partition值但有 key 的情況下,將 key 的 Hash 值與 topic 的Partition值進(jìn)行取余得到Partition值
- 既沒有Partition值又沒有 key 值的情況下,第一次調(diào)用時隨機(jī)生成一個整數(shù)(后面每次調(diào)用在這個整數(shù)上自增),將這個值與Topic可用的Partition總數(shù)取余得到Parittion值,也就是常說的 round-robin 算法
- 方便在集群中擴(kuò)展,每個 Partition 可用通過調(diào)整以適應(yīng)它所在的機(jī)器,而一個Topic又可以有多個Partition組成,因此整個集群就可以適應(yīng)任意大小的數(shù)據(jù)了
- 可以提高并發(fā),因為可以以Partition為單位進(jìn)行讀寫
- 一條消息發(fā)過來首先會被封裝成一個 ProducerRecord 對象
- 對該對象進(jìn)行序列化處理(可以使用默認(rèn),也可以自定義序列化)
- 對消息進(jìn)行分區(qū)處理,分區(qū)的時候需要獲取集群的元數(shù)據(jù),決定這個消息會被發(fā)送到哪個主題的哪個分區(qū)
- 分好區(qū)的消息不會直接發(fā)送到服務(wù)端,而是放入生產(chǎn)者的緩存區(qū),多條消息會被封裝成一個批次(Batch),默認(rèn)一個批次的大小是 16KB
- Sender 線程啟動以后會從緩存里面去獲取可以發(fā)送的批次
- Sender 線程把一個一個批次發(fā)送到服務(wù)端
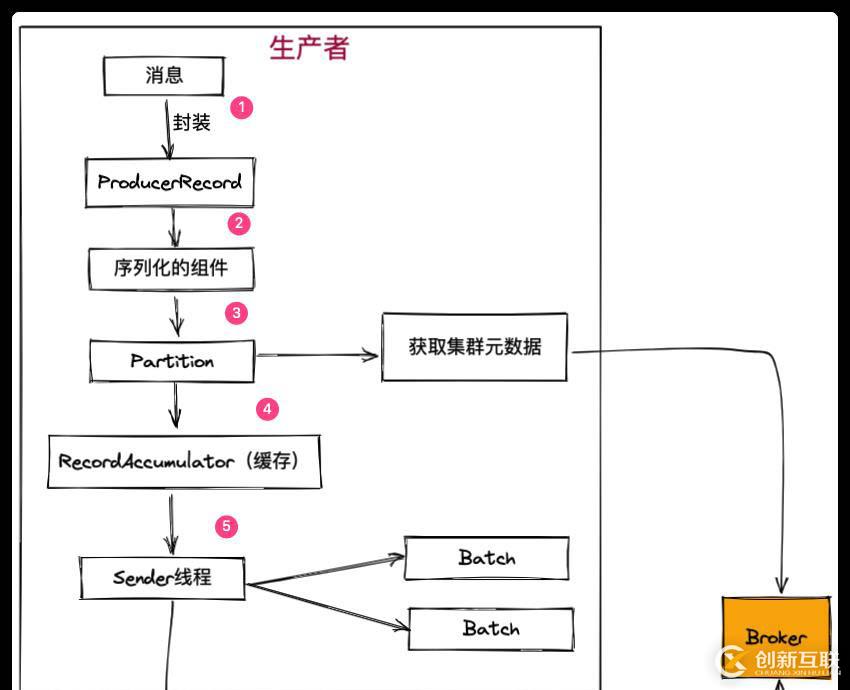
在Kafka 中 Producer 可以 Batch的方式推送數(shù)據(jù)達(dá)到提高效率的作用。Kafka Producer 可以將消息在內(nèi)存中累積到一定數(shù)量后作為一個 Batch 發(fā)送請求。Batch 的數(shù)量大小可以通過 Producer 的參數(shù)進(jìn)行控制,可以從三個維度進(jìn)行控制
- 累計的消息的數(shù)量(如500條)
- 累計的時間間隔(如100ms)
- 累計的數(shù)據(jù)大小(如64KB)
通過增加 Batch 的大小,可以減少網(wǎng)絡(luò)請求和磁盤I/O的頻次,具體參數(shù)配置需要在效率和時效性做一個權(quán)衡。
11、Kafka 消息的消費(fèi)模式Kafka采用大部分消息系統(tǒng)遵循的傳統(tǒng)模式:Producer將消息推送到Broker,Consumer從Broker獲取消息。
如果采用 Push 模式,則Consumer難以處理不同速率的上游推送消息。
采用 Pull 模式的好處是Consumer可以自主決定是否批量的從Broker拉取數(shù)據(jù)。Pull模式有個缺點(diǎn)是,如果Broker沒有可供消費(fèi)的消息,將導(dǎo)致Consumer不斷在循環(huán)中輪詢,直到新消息到達(dá)。為了避免這點(diǎn),Kafka有個參數(shù)可以讓Consumer阻塞直到新消息到達(dá)。
12、Kafka 如何實現(xiàn)負(fù)載均衡與故障轉(zhuǎn)移負(fù)載均衡是指讓系統(tǒng)的負(fù)載根據(jù)一定的規(guī)則均衡地分配在所有參與工作的服務(wù)器上,從而大限度保證系統(tǒng)整體運(yùn)行效率與穩(wěn)定性
負(fù)載均衡
Kakfa 的負(fù)載均衡就是每個 Broker 都有均等的機(jī)會為 Kafka 的客戶端(生產(chǎn)者與消費(fèi)者)提供服務(wù),可以負(fù)載分散到所有集群中的機(jī)器上。Kafka 通過智能化的分區(qū)領(lǐng)導(dǎo)者選舉來實現(xiàn)負(fù)載均衡,提供智能化的 Leader 選舉算法,可在集群的所有機(jī)器上均勻分散各個Partition的Leader,從而整體上實現(xiàn)負(fù)載均衡。
故障轉(zhuǎn)移
Kafka 的故障轉(zhuǎn)移是通過使用會話機(jī)制實現(xiàn)的,每臺 Kafka 服務(wù)器啟動后會以會話的形式把自己注冊到 Zookeeper 服務(wù)器上。一旦服務(wù)器運(yùn)轉(zhuǎn)出現(xiàn)問題,就會導(dǎo)致與Zookeeper 的會話不能維持從而超時斷連,此時Kafka集群會選舉出另一臺服務(wù)器來完全替代這臺服務(wù)器繼續(xù)提供服務(wù)。
13、Kafka 中 Zookeeper 的作用Kafka 是一個使用 Zookeeper 構(gòu)建的分布式系統(tǒng)。Kafka 的各 Broker 在啟動時都要在Zookeeper上注冊,由Zookeeper統(tǒng)一協(xié)調(diào)管理。如果任何節(jié)點(diǎn)失敗,可通過Zookeeper從先前提交的偏移量中恢復(fù),因為它會做周期性提交偏移量工作。同一個Topic的消息會被分成多個分區(qū)并將其分布在多個Broker上,這些分區(qū)信息及與Broker的對應(yīng)關(guān)系也是Zookeeper在維護(hù)。
14、Kafka 提供了哪些系統(tǒng)工具- Kafka 遷移工具:它有助于將代理從一個版本遷移到另一個版本
- Mirror Maker:Mirror Maker 工具有助于將一個 Kafka 集群的鏡像提供給另一個
- 消費(fèi)者檢查:對于指定的主題集和消費(fèi)者組,可顯示主題、分區(qū)、所有者
Consumer Group 是Kafka獨(dú)有的可擴(kuò)展且具有容錯性的消費(fèi)者機(jī)制。一個組內(nèi)可以有多個Consumer,它們共享一個全局唯一的Group ID。組內(nèi)的所有Consumer協(xié)調(diào)在一起來消費(fèi)訂閱主題(Topic)內(nèi)的所有分區(qū)(Partition)。當(dāng)然,每個Partition只能由同一個Consumer Group內(nèi)的一個Consumer 來消費(fèi)。消費(fèi)組內(nèi)的消費(fèi)者可以使用多線程的方式實現(xiàn),消費(fèi)者的數(shù)量通常不超過分區(qū)的數(shù)量,且二者最好保持整數(shù)倍的關(guān)系,這樣不會造成有空閑的消費(fèi)者。
Consumer 訂閱的是Topic的Partition,而不是Message。所以在同一時間點(diǎn)上,訂閱到同一個分區(qū)的Consumer必然屬于不同的Consumer Group
Consumer Group與Consumer的關(guān)系是動態(tài)維護(hù)的,當(dāng)一個Consumer進(jìn)程掛掉或者是卡住時,該Consumer所訂閱的Partition會被重新分配到改組內(nèi)的其他Consumer上,當(dāng)一個Consumer加入到一個Consumer Group中時,同樣會從其他的Consumer中分配出一個或者多個Partition到這個新加入的Consumer。
負(fù)載均衡
當(dāng)啟動一個Consumer時,會指定它要加入的Group,使用的配置項是:Group.id
為了維持Consumer與Consumer Group之間的關(guān)系,Consumer 會周期性地發(fā)送 hearbeat 到 coodinator(協(xié)調(diào)者),如果有 hearbeat 超時或未收到 hearbeat,coordinator 會認(rèn)為該Consumer已經(jīng)退出,那么它所訂閱的Partition會分配到同一組內(nèi)的其他Consumer上,這個過程稱為 rebalance(再平衡)
16、Kafka 中消息偏移的作用生產(chǎn)過程中給分區(qū)中的消息提供一個順序ID號,稱之為偏移量,偏移量的主要作用為了唯一地區(qū)別分區(qū)中的每條消息。Kafka的存儲文件都是按照offset.kafka來命名
17、 生產(chǎn)過程中何時會發(fā)生QueueFullExpection以及如何處理何時發(fā)生
當(dāng)生產(chǎn)者試圖發(fā)送消息的速度快于Broker可以處理的速度時,通常會發(fā)生 QueueFullException
如何解決
首先先進(jìn)行判斷生產(chǎn)者是否能夠降低生產(chǎn)速率,如果生產(chǎn)者不能阻止這種情況,為了處理增加的負(fù)載,用戶需要添加足夠的 Broker。或者選擇生產(chǎn)阻塞,設(shè)置Queue.enQueueTimeout.ms為 -1,通過這樣處理,如果隊列已滿的情況,生產(chǎn)者將組織而不是刪除消息。或者容忍這種異常,進(jìn)行消息丟棄。
Cosumer 消費(fèi)消息時,想Broker 發(fā)出fetch請求去消費(fèi)特定分區(qū)的消息,Consumer 可以通過指定消息在日志中的偏移量 offset,就可以從這個位置開始消息消息,Consumer 擁有了 offset 的控制權(quán),也可以向后回滾去重新消費(fèi)之前的消息。
也可以使用seek(Long topicPartition)來指定消費(fèi)的位置。
Kafka 中的 Partition 是有序消息日志,為了實現(xiàn)高可用性,需要采用備份機(jī)制,將相同的數(shù)據(jù)復(fù)制到多個Broker上,而這些備份日志就是 Replica,目的是為了 防止數(shù)據(jù)丟失。
所有Partition 的副本默認(rèn)情況下都會均勻地分布到所有 Broker 上,一旦領(lǐng)導(dǎo)者副本所在的Broker宕機(jī),Kafka 會從追隨者副本中選舉出新的領(lǐng)導(dǎo)者繼續(xù)提供服務(wù)。
Leader: 副本中的領(lǐng)導(dǎo)者。負(fù)責(zé)對外提供服務(wù),與客戶端進(jìn)行交互。生產(chǎn)者總是向 Leader副本些消息,消費(fèi)者總是從 Leader 讀消息
Follower: 副本中的追隨者。被動地追隨 Leader,不能與外界進(jìn)行交付。只是向Leader發(fā)送消息,請求Leader把最新生產(chǎn)的消息發(fā)給它,進(jìn)而保持同步。
20、Replica 的重要性Replica 可以確保發(fā)布的消息不會丟失,保證了Kafka的高可用性。并且可以在發(fā)生任何機(jī)器錯誤、程序錯誤或軟件升級、擴(kuò)容時都能生產(chǎn)使用。
21、Kafka 中的 Geo-Replication 是什么Kafka官方提供了MirrorMaker組件,作為跨集群的流數(shù)據(jù)同步方案。借助MirrorMaker,消息可以跨多個數(shù)據(jù)中心或云區(qū)域進(jìn)行復(fù)制。您可以在主動/被動場景中將其用于備份和恢復(fù),或者在主動/主動方案中將數(shù)據(jù)放置得更靠近用戶,或支持?jǐn)?shù)據(jù)本地化要求。
它的實現(xiàn)原理比較簡單,就是通過從源集群消費(fèi)消息,然后將消息生產(chǎn)到目標(biāo)集群,即普通的消息生產(chǎn)和消費(fèi)。用戶只要通過簡單的Consumer配置和Producer配置,然后啟動Mirror,就可以實現(xiàn)集群之間的準(zhǔn)實時的數(shù)據(jù)同步.
22、Kafka 中 AR、ISR、OSR 三者的概念AR:分區(qū)中所有副本稱為 ARISR:所有與主副本保持一定程度同步的副本(包括主副本)稱為 ISROSR:與主副本滯后過多的副本組成 OSR
Leader 會維護(hù)一個與自己基本保持同步的Replica列表,該列表稱為ISR,每個Partition都會有一個ISR,而且是由Leader動態(tài)維護(hù)。所謂動態(tài)維護(hù),就是說如果一個Follower比一個Leader落后太多,或者超過一定時間未發(fā)起數(shù)據(jù)復(fù)制請求,則Leader將其從ISR中移除。當(dāng)ISR中所有Replica都向Leader發(fā)送ACK(Acknowledgement確認(rèn))時,Leader才commit。
24、分區(qū)副本中的 Leader 如果宕機(jī)但 ISR 卻為空該如何處理可以通過配置unclean.leader.election:
- true:允許 OSR 成為 Leader,但是 OSR 的消息較為滯后,可能會出現(xiàn)消息不一致的問題
- false:會一直等待舊 leader 恢復(fù)正常,降低了可用性
- Broker必須可以維護(hù)和ZooKeeper的連接,Zookeeper通過心跳機(jī)制檢查每個結(jié)點(diǎn)的連接。
- 如果Broker是個Follower,它必須能及時同步Leader的寫操作,延時不能太久。
Kafka可以接收的大消息默認(rèn)為1000000字節(jié),如果想調(diào)整它的大小,可在Broker中修改配置參數(shù):Message.max.bytes的值
27、Kafka 的 ACK 機(jī)制但要注意的是,修改這個值,還要同時注意其他對應(yīng)的參數(shù)值是正確的,否則就可能引發(fā)一些系統(tǒng)異常。首先這個值要比消費(fèi)端的fetch.Message.max.bytes(默認(rèn)值1MB,表示消費(fèi)者能讀取的大消息的字節(jié)數(shù))參數(shù)值要小才是正確的設(shè)置,否則Broker就會因為消費(fèi)端無法使用這個消息而掛起。
Kafka的Producer有三種ack機(jī)制,參數(shù)值有0、1 和 -1
- 0: 相當(dāng)于異步操作,Producer 不需要Leader給予回復(fù),發(fā)送完就認(rèn)為成功,繼續(xù)發(fā)送下一條(批)Message。此機(jī)制具有最低延遲,但是持久性可靠性也最差,當(dāng)服務(wù)器發(fā)生故障時,很可能發(fā)生數(shù)據(jù)丟失。
- 1: Kafka 默認(rèn)的設(shè)置。表示 Producer 要 Leader 確認(rèn)已成功接收數(shù)據(jù)才發(fā)送下一條(批)Message。不過 Leader 宕機(jī),F(xiàn)ollower 尚未復(fù)制的情況下,數(shù)據(jù)就會丟失。此機(jī)制提供了較好的持久性和較低的延遲性。
- -1: Leader 接收到消息之后,還必須要求ISR列表里跟Leader保持同步的那些Follower都確認(rèn)消息已同步,Producer 才發(fā)送下一條(批)Message。此機(jī)制持久性可靠性最好,但延時性最差。
在Kafka中,Producers將消息推送給Broker端,在Consumer和Broker建立連接之后,會主動去 Pull(或者說Fetch)消息。這種模式有些優(yōu)點(diǎn),首先Consumer端可以根據(jù)自己的消費(fèi)能力適時的去fetch消息并處理,且可以控制消息消費(fèi)的進(jìn)度(offset);此外,消費(fèi)者可以控制每次消費(fèi)的數(shù),實現(xiàn)批量消費(fèi)。
29、Kafka 提供的API有哪些Kafka 提供了兩套 Consumer API,分為 High-level API 和 Sample API
Sample API
這是一個底層API,它維持了一個與單一 Broker 的連接,并且這個API 是完全無狀態(tài)的,每次請求都需要指定 offset 值,因此這套 API 也是最靈活的。
High-level API
該API封裝了對集群中一系列Broker的訪問,可以透明地消費(fèi)下一個Topic,它自己維護(hù)了已消費(fèi)消息的狀態(tài),即每次消費(fèi)的都會下一個消息。High-level API 還支持以組的形式消費(fèi)Topic,如果 Consumers 有同一個組名,那么Kafka就相當(dāng)于一個隊列消息服務(wù),而各個 Consumer 均衡地消費(fèi)相應(yīng)Partition中的數(shù)據(jù)。若Consumers有不同的組名,那么此時Kafka就相當(dāng)于一個廣播服務(wù),會把Topic中的所有消息廣播到每個Consumer
30、Kafka 的Topic中 Partition 數(shù)據(jù)是怎么存儲到磁盤的Topic 中的多個 Partition 以文件夾的形式保存到 Broker,每個分區(qū)序號從0遞增,且消息有序。Partition 文件下有多個Segment(xxx.index,xxx.log),Segment文件里的大小和配置文件大小一致。默認(rèn)為1GB,但可以根據(jù)實際需要修改。如果大小大于1GB時,會滾動一個新的Segment并且以上一個Segment最后一條消息的偏移量命名。
31、Kafka 創(chuàng)建Topic后如何將分區(qū)放置到不同的 Broker 中Kafka創(chuàng)建Topic將分區(qū)放置到不同的Broker時遵循以下規(guī)則:
- 副本因子不能大于Broker的個數(shù)。
- 第一個分區(qū)(編號為0)的第一個副本放置位置是隨機(jī)從Broker List中選擇的。
- 其他分區(qū)的第一個副本放置位置相對于第0個分區(qū)依次往后移。也就是如果有3個Broker,3個分區(qū),假設(shè)第一個分區(qū)放在第二個Broker上,那么第二個分區(qū)將會放在第三個Broker上;第三個分區(qū)將會放在第一個Broker上,更多Broker與更多分區(qū)依此類推。剩余的副本相對于第一個副本放置位置其實是由
nextReplicaShift決定的,而這個數(shù)也是隨機(jī)產(chǎn)生的。
概念
保留期內(nèi)保留了Kafka群集中的所有已發(fā)布消息,超過保期的數(shù)據(jù)將被按清理策略進(jìn)行清理。默認(rèn)保留時間是7天,如果想修改時間,在server.properties里更改參數(shù)log.retention.hours/minutes/ms的值便可。
清理策略
- 刪除:
log.cleanup.policy=delete表示啟用刪除策略,這也是默認(rèn)策略。一開始只是標(biāo)記為delete,文件無法被索引。只有過了log.Segment.delete.delay.ms這個參數(shù)設(shè)置的時間,才會真正被刪除。 - 壓縮:
log.cleanup.policy=compact表示啟用壓縮策略,將數(shù)據(jù)壓縮,只保留每個Key最后一個版本的數(shù)據(jù)。首先在Broker的配置中設(shè)置log.cleaner.enable=true啟用 cleaner,這個默認(rèn)是關(guān)閉的。
Kafka一個Message由固定長度的header和一個變長的消息體body組成。將Message存儲在日志時采用不同于Producer發(fā)送的消息格式。每個日志文件都是一個log entries(日志項)序列:
- 每一個log entry包含一個四字節(jié)整型數(shù)(Message長度,值為1+4+N)。
- 1個字節(jié)的magic,magic表示本次發(fā)布Kafka服務(wù)程序協(xié)議版本號。
- 4個字節(jié)的CRC32值,CRC32用于校驗Message。
- 最終是N個字節(jié)的消息數(shù)據(jù)。每條消息都有一個當(dāng)前Partition下唯一的64位offset。
34、Kafka 是否支持多租戶隔離Kafka沒有限定單個消息的大小,但一般推薦消息大小不要超過1MB,通常一般消息大小都在1~10KB之間。
多租戶技術(shù)(multi-tenancy technology)是一種軟件架構(gòu)技術(shù),它是實現(xiàn)如何在多用戶的環(huán)境下共用相同的系統(tǒng)或程序組件,并且仍可確保各用戶間數(shù)據(jù)的隔離性。
解決方案
通過配置哪個主題可以生產(chǎn)或消費(fèi)數(shù)據(jù)來啟用多租戶,也有對配額的操作支持。管理員可以對請求定義和強(qiáng)制配額,以控制客戶端使用的Broker資源。
35、Kafka 的日志分段策略與刷新策略日志分段(Segment)策略
log.roll.hours/ms:日志滾動的周期時間,到達(dá)指定周期時間時,強(qiáng)制生成一個新的Segment,默認(rèn)值168h(7day)。log.Segment.bytes:每個Segment的大容量。到達(dá)指定容量時,將強(qiáng)制生成一個新的Segment。默認(rèn)值1GB(-1代表不限制)。log.retention.check.interval.ms:日志片段文件檢查的周期時間。默認(rèn)值60000ms。
日志刷新策略
Kafka的日志實際上是開始是在緩存中的,然后根據(jù)實際參數(shù)配置的策略定期一批一批寫入到日志文件中,以提高吞吐量。
log.flush.interval.Messages:消息達(dá)到多少條時將數(shù)據(jù)寫入到日志文件。默認(rèn)值為10000。log.flush.interval.ms:當(dāng)達(dá)到該時間時,強(qiáng)制執(zhí)行一次flush。默認(rèn)值為null。log.flush.scheduler.interval.ms:周期性檢查,是否需要將信息flush。默認(rèn)為很大的值。
Kafka動態(tài)維護(hù)了一個同步狀態(tài)的副本的集合(a set of In-SyncReplicas),簡稱ISR,在這個集合中的結(jié)點(diǎn)都是和Leader保持高度一致的,任何一條消息只有被這個集合中的每個結(jié)點(diǎn)讀取并追加到日志中,才會向外部通知“這個消息已經(jīng)被提交”。
kafka 通過配置producer.type來確定是異步還是同步,默認(rèn)是同步
同步復(fù)制
Producer 會先通過Zookeeper識別到Leader,然后向 Leader 發(fā)送消息,Leader 收到消息后寫入到本地 log文件。這個時候Follower 再向 Leader Pull 消息,Pull 回來的消息會寫入的本地 log 中,寫入完成后會向 Leader 發(fā)送 Ack 回執(zhí),等到 Leader 收到所有 Follower 的回執(zhí)之后,才會向 Producer 回傳 Ack。
異步復(fù)制
Kafka 中 Producer 異步發(fā)送消息是基于同步發(fā)送消息的接口來實現(xiàn)的,異步發(fā)送消息的實現(xiàn)很簡單,客戶端消息發(fā)送過來以后,會先放入一個BlackingQueue隊列中然后就返回了。Producer 再開啟一個線程ProducerSendTread不斷從隊列中取出消息,然后調(diào)用同步發(fā)送消息的接口將消息發(fā)送給 Broker。
37、Kafka 中什么情況下會出現(xiàn)消息丟失/不一致的問題Producer的這種在內(nèi)存緩存消息,當(dāng)累計達(dá)到閥值時批量發(fā)送請求,小數(shù)據(jù)I/O太多,會拖慢整體的網(wǎng)絡(luò)延遲,批量延遲發(fā)送事實上提升了網(wǎng)絡(luò)效率。但是如果在達(dá)到閥值前,Producer不可用了,緩存的數(shù)據(jù)將會丟失。
消息發(fā)送時
消息發(fā)送有兩種方式:同步 - sync和異步 - async。默認(rèn)是同步的方式,可以通過 producer.type 屬性進(jìn)行配置,kafka 也可以通過配置 acks 屬性來確認(rèn)消息的生產(chǎn)
0:表示不進(jìn)行消息接收是否成功的確認(rèn)1:表示當(dāng) leader 接收成功時的確認(rèn)-1:表示 leader 和 follower 都接收成功的確認(rèn)
當(dāng) acks = 0 時,不和 Kafka 進(jìn)行消息接收確認(rèn),可能會因為網(wǎng)絡(luò)異常,緩沖區(qū)滿的問題,導(dǎo)致消息丟失
當(dāng) acks = 1 時,只有 leader 同步成功而 follower 尚未完成同步,如果 leader 掛了,就會造成數(shù)據(jù)丟失
消息消費(fèi)時
Kafka 有兩個消息消費(fèi)的 consumer 接口,分別是low-level和hign-level
low-level:消費(fèi)者自己維護(hù) offset 等值,可以實現(xiàn)對 kafka 的完全控制high-level:封裝了對 partition 和 offset,使用簡單
如果使用高級接口,可能存在一個消費(fèi)者提取了一個消息后便提交了 offset,那么還沒來得及消費(fèi)就已經(jīng)掛了,下次消費(fèi)時的數(shù)據(jù)就是 offset + 1 的位置,那么原先 offset 的數(shù)據(jù)就丟失了。
38、Kafka 作為流處理平臺的特點(diǎn)流處理就是連續(xù)、實時、并發(fā)和以逐條記錄的方式處理數(shù)據(jù)的意思。Kafka 是一個分布式流處理平臺,它的高吞吐量、低延時、高可靠性、容錯性、高可擴(kuò)展性都使得Kafka非常適合作為流式平臺。
- 它是一個簡單的、輕量級的Java類庫,能夠被集成到任何Java應(yīng)用中
- 除了Kafka之外沒有任何其他的依賴,利用Kafka的分區(qū)模型支持水平擴(kuò)容和保證順序性
- 支持本地狀態(tài)容錯,可以執(zhí)行非常快速有效的有狀態(tài)操作
- 支持 eexactly-once 語義
- 支持一次處理一條記錄,實現(xiàn) ms 級的延遲
活鎖的概念:消費(fèi)者持續(xù)的維持心跳,但沒有進(jìn)行消息處理。
為了預(yù)防消費(fèi)者在這種情況一直持有分區(qū),通常會利用max.poll.interval.ms活躍檢測機(jī)制,如果調(diào)用 Poll 的頻率大于大間隔,那么消費(fèi)者將會主動離開消費(fèi)組,以便其他消費(fèi)者接管該分區(qū)
Kafka 的消費(fèi)單元是 Partition,同一個 Partition 使用 offset 作為唯一標(biāo)識保證順序性,但這只是保證了在 Partition 內(nèi)部的順序性而不是 Topic 中的順序,因此我們需要將所有消息發(fā)往統(tǒng)一 Partition 才能保證消息順序消費(fèi),那么可以在發(fā)送的時候指定 MessageKey,同一個 key 的消息會發(fā)到同一個 Partition 中。
以上便是本篇的全部內(nèi)容,不要空談,不要貪懶,和小菜一起做個吹著牛X做架構(gòu)的程序猿吧~點(diǎn)個關(guān)注做個伴,讓小菜不再孤單。咱們下文見!
今天的你多努力一點(diǎn),明天的你就能少說一句求人的話!
我是小菜,一個和你一起變強(qiáng)的男人。
💋微信公眾號已開啟,菜農(nóng)曰,沒關(guān)注的同學(xué)們記得關(guān)注哦!
你是否還在尋找穩(wěn)定的海外服務(wù)器提供商?創(chuàng)新互聯(lián)www.cdcxhl.cn海外機(jī)房具備T級流量清洗系統(tǒng)配攻擊溯源,準(zhǔn)確流量調(diào)度確保服務(wù)器高可用性,企業(yè)級服務(wù)器適合批量采購,新人活動首月15元起,快前往官網(wǎng)查看詳情吧
當(dāng)前題目:刨根問底Kafka,面試過程真好使-創(chuàng)新互聯(lián)
文章網(wǎng)址:http://m.newbst.com/article14/hjege.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供定制網(wǎng)站、品牌網(wǎng)站設(shè)計、網(wǎng)站設(shè)計、企業(yè)建站、微信公眾號、小程序開發(fā)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容

- 免費(fèi)虛擬主機(jī)是在變相的“消費(fèi)” 2022-05-23
- 服務(wù)器、云服務(wù)器與虛擬主機(jī)有什么區(qū)別? 2022-10-05
- 網(wǎng)站空間虛擬主機(jī)空間虛擬主機(jī)配置域名注冊云服務(wù)器 2016-11-05
- 美國的云主機(jī)和虛擬主機(jī)的區(qū)別是什么 2022-10-05
- 如何選擇適合自己的云主機(jī)?云主機(jī)和虛擬主機(jī)有何不同? 2022-10-02
- 新手選購虛擬主機(jī)N個注意事項 2022-10-02
- 網(wǎng)站建設(shè)中測試虛擬主機(jī)的速度的兩種方法 2016-11-10
- 虛擬主機(jī)對SEO優(yōu)化有哪些影響 2016-01-20
- 選擇優(yōu)質(zhì)虛擬主機(jī)需要注意的六大要素 2021-08-16
- 如何選擇適合php的虛擬主機(jī) 2022-07-29
- apache虛擬主機(jī)中設(shè)置泛域名解析的方法 2022-10-03
- 初步體驗百度云虛擬主機(jī)BCH 2021-01-27