python獲取js動態加載數據的方法
這篇文章給大家分享的是有關python獲取js動態加載數據的方法的內容。小編覺得挺實用的,因此分享給大家做個參考。一起跟隨小編過來看看吧。
創新互聯:公司2013年成立為各行業開拓出企業自己的“網站建設”服務,為1000多家公司企業提供了專業的成都網站設計、成都網站建設、網頁設計和網站推廣服務, 按需網站建設由設計師親自精心設計,設計的效果完全按照客戶的要求,并適當的提出合理的建議,擁有的視覺效果,策劃師分析客戶的同行競爭對手,根據客戶的實際情況給出合理的網站構架,制作客戶同行業具有領先地位的。

我們在做網頁抓取的時候,一般來說使用urllib和urllib2就能滿足大部分需求。
但是有時候我們遇見那種使用js動態加載的網頁。就會發現urllib只能抓出一個部分內容空白的網頁。就像下面百度圖片的結果頁:
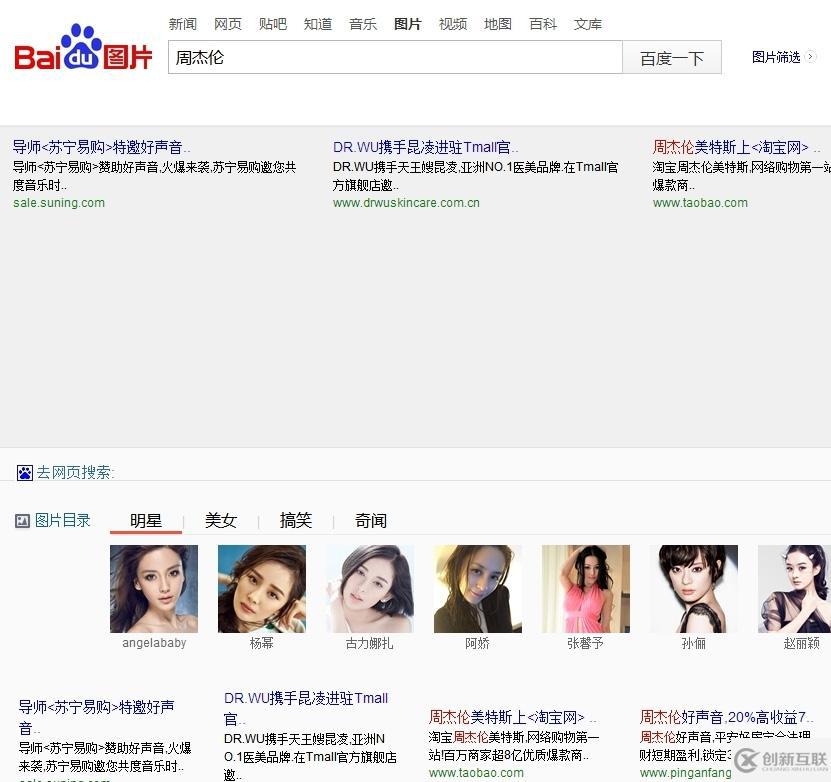
審查元素之后,發現百度圖片中,顯示圖片的div為:pullimages
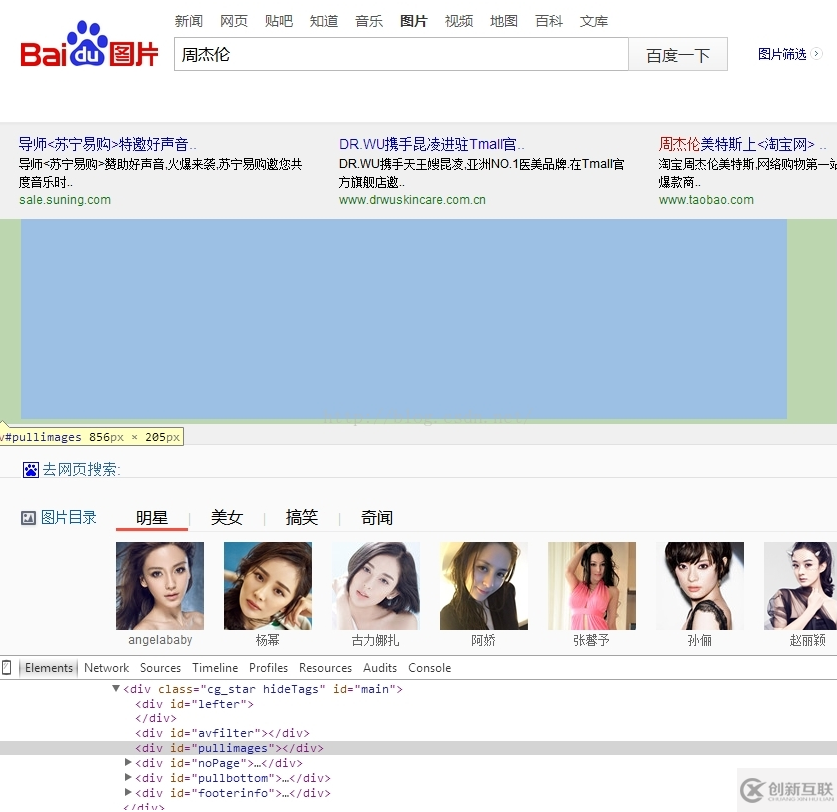
這個div里面的內容是動態加載的。而使用urllib&urllib2是抓取不到的。
要抓取動態加載的元素,首先考慮使用selenium來調用瀏覽器進行抓取。
而我們運行的環境是linux,最理想的方法是在無界面情況下進行抓取,所以使用selenium+phantomjs來進行無界面抓取。
phantomjs是什么呢?它是一個基于webkit內核的無頭瀏覽器,即沒有UI界面,即它就是一個瀏覽器。
selenium和phantomjs的安裝配置可以google,這里就略過不談了。
代碼如下:
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#如果不方便配置環境變量。就使用phantomjs的絕對路徑也可以
driver.get('http://image.baidu.com/i?ie=utf-8&word=%E5%91%A8%E6%9D%B0%E4%BC%A6')
#抓取了百度圖片,query:周杰倫
driver.page_source
#這就是返回的頁面內容了,與urllib2.urlopen().read()的效果是類似的,但比urllib2強在能抓取到動態渲染后的內容。
driver.quit()到這里。就抓取動態頁面成功了。
感謝各位的閱讀!關于python獲取js動態加載數據的方法就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
網頁標題:python獲取js動態加載數據的方法
當前鏈接:http://m.newbst.com/article16/gpghdg.html
成都網站建設公司_創新互聯,為您提供服務器托管、網站維護、網站建設、網站排名、域名注冊、手機網站建設
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 外貿建站和推廣如何做 2021-01-28
- 什么是外貿建站?建站前都有哪些必須了解的? 2015-08-19
- 外貿建站前必看的四大技巧及優化系統 2022-05-27
- 做外貿建站好不好?這幾個誤區要注意了 2015-04-27
- 越秀區小北路外貿建站,越秀區小北路外貿網站建設公司 2016-04-06
- 成都外貿建站公司哪家好? 2015-03-21
- 外貿建站域名該怎么選? 2015-06-08
- 外貿建站選韓國vps主機適合嗎? 2022-10-07
- 成都網站建設過程中關于外貿建站 2018-06-13
- 外貿建站之營銷型網站 2016-03-26
- 成都外貿建站怎樣才能有效果 2015-04-01
- 外貿建站是否應該選擇響應式網站設計? 2015-12-18