一個(gè)容易被忽略的SQL調(diào)優(yōu)技巧---orderby字段到底要不要加入索引
對(duì)于SQL調(diào)優(yōu),要調(diào)就調(diào)到極致,小編并不是處女座,而是因?yàn)樵谝粋€(gè)并發(fā)量很大的業(yè)務(wù)系統(tǒng)中,對(duì)于頻繁執(zhí)行的單條SQL性能的提升,可能對(duì)整體數(shù)據(jù)庫(kù)的性能提升都有很大的意義。
但是遇到order by字段后面的字段,特別是當(dāng)這個(gè)字段不在過(guò)濾條件中時(shí),小編就會(huì)心里打鼓,是加到索引里面呢,還是不加到索引里面呢,加進(jìn)去會(huì)不會(huì)沒(méi)有起到提升性能的作用,反而讓索引變得更加復(fù)雜,給系統(tǒng)帶來(lái)不必要的額外負(fù)擔(dān),“偷雞不成蝕把米”,開(kāi)個(gè)玩笑。但是如果直接忽略掉這個(gè)問(wèn)題,很可能這個(gè)提升系統(tǒng)性能的機(jī)會(huì)就被錯(cuò)過(guò)了。
所以今天小編就和大家探討一下,面對(duì)order by字段后面的條件,特別是這個(gè)條件不在過(guò)濾條件中時(shí),到底要不要加入索引中,對(duì)于SQL調(diào)優(yōu)這筆賬,索引中加入order by字段,是賺了還是賠了?
創(chuàng)新新互聯(lián),憑借十載的做網(wǎng)站、網(wǎng)站制作經(jīng)驗(yàn),本著真心·誠(chéng)心服務(wù)的企業(yè)理念服務(wù)于成都中小企業(yè)設(shè)計(jì)網(wǎng)站有1000+案例。做網(wǎng)站建設(shè),選創(chuàng)新互聯(lián)建站。
Part 1
空話(huà)不多說(shuō),先來(lái)一個(gè)小實(shí)驗(yàn),熱一下身。通過(guò)多次復(fù)制dba_objects中的數(shù)據(jù),生成測(cè)試表T1,大約1000萬(wàn)行數(shù)據(jù)。做一個(gè)簡(jiǎn)單的查詢(xún),查詢(xún)T1表中object_id最小的10行數(shù)據(jù),select * from (select * from T1 order by object_id) where rownum<=10,耗時(shí)‘Elapsed: 00:00:35.92’,執(zhí)行計(jì)劃如下: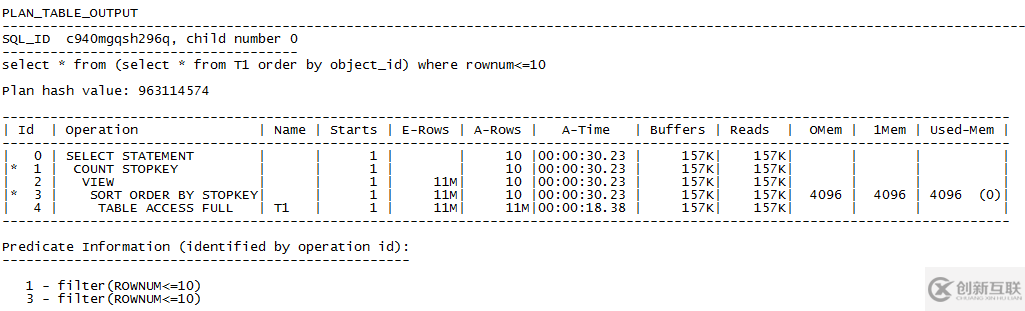
執(zhí)行計(jì)劃中可以看到,先作了一個(gè)全表掃,取到了結(jié)果集11M行(可以粗略理解為11百萬(wàn)行,這個(gè)測(cè)試表T1行數(shù)為11943842)。然后作了一個(gè)排序,截取最小的10條記錄,最后返回結(jié)果。下面我們?cè)趏bject_id字段上建一個(gè)索引I_T1_ORDER3,作一個(gè)比較。
耗時(shí)從剛才的35秒,直接降到了 ‘Elapsed: 00:00:00.01’,提升性能的效果非常明顯。索引和執(zhí)行計(jì)劃如下: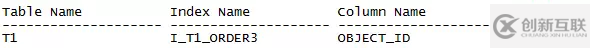
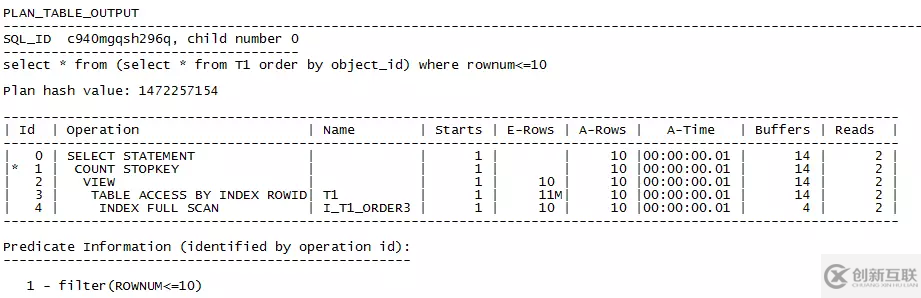
從執(zhí)行計(jì)劃中可以看到,優(yōu)化器直接從索引中找到了最小的10條記錄,然后回表取得結(jié)果集返回。相比上一個(gè)執(zhí)行計(jì)劃,省去了全表掃描,省去了排序,所以執(zhí)行時(shí)間和系統(tǒng)資源消耗都大大減少。
在這里作一個(gè)簡(jiǎn)單的分析,首先索引和數(shù)據(jù)不同,是按照有序的排列存儲(chǔ)的,當(dāng)結(jié)果集要求按照順序取得一部分?jǐn)?shù)據(jù)時(shí),索引的功效會(huì)體現(xiàn)的非常明顯,本次查詢(xún)就是要取得object_id最小的10條記錄。其次,建立索引系統(tǒng)只需要消耗一次資源完成排序過(guò)程,而如果沒(méi)有索引,執(zhí)行不同的語(yǔ)句可能每次都要經(jīng)歷排序的過(guò)程,會(huì)消耗更多的系統(tǒng)資源。從這個(gè)實(shí)驗(yàn)看,在order by字段建索引是非常劃算的,而且order by字段并不一定非要加入到where條件中也可以生效。
這里小編要和大家分享一個(gè)自己踩到的“坑”,就是小編起初在建了索引I_T1_ORDER3后,這條查詢(xún)語(yǔ)句的執(zhí)行計(jì)劃并不選擇索引,增加了hint提示也不選擇,小編都有點(diǎn)懷疑人生了,明顯使用索引會(huì)好,為什么優(yōu)化器偏偏不選擇索引呢,而且是加了hint也不走。在修改object_id列為非空屬性(NOT NULL)后,優(yōu)化器才選擇了這個(gè)索引。小編這里是這么理解的,如果這一列存在NULL值,NULL值是沒(méi)有大小這一說(shuō)法的,而且不會(huì)被保存在索引中。如果優(yōu)化器無(wú)法確定該列沒(méi)有NULL值,為了保證結(jié)果集的準(zhǔn)確性,寧愿選擇更慢的全表掃描,也不會(huì)選擇走可能存在NULL的索引,即使用戶(hù)指定了hint也不會(huì)選擇(這里的幾句話(huà)有點(diǎn)繞,大家耐心讀一下)。從這一點(diǎn)來(lái)看,開(kāi)發(fā)Oracle優(yōu)化器的小伙伴是非常靠譜的。
Part 2
上面的實(shí)驗(yàn)中order by字段加入索引的作用非常明顯。可是在實(shí)際生產(chǎn)環(huán)境中,能有這么簡(jiǎn)單的SQL來(lái)給DBA調(diào)優(yōu)的機(jī)會(huì)并不多,實(shí)際生產(chǎn)中的SQL往往要更復(fù)雜一些。下面我們就把測(cè)試變得復(fù)雜一點(diǎn),復(fù)制測(cè)試表T1,生成測(cè)試表T2,查詢(xún)object_type類(lèi)似INDEX中object_id最小的10條記錄,select * from (select * from T2 where object_type like '%INDEX%' order by object_id) where rownum<=10。
這條語(yǔ)句比第一個(gè)實(shí)驗(yàn)中多了過(guò)濾條件,但是使用了like方法。按通常的經(jīng)驗(yàn)建索引首先會(huì)考慮where條件后的字段,但是在使用like的過(guò)濾條件上建立索引,效果可能并不好。可是如果這條語(yǔ)句是業(yè)務(wù)系統(tǒng)中執(zhí)行頻率非常高的語(yǔ)句呢,我們還是硬著頭皮優(yōu)化一下吧。先看一下沒(méi)有索引的情況。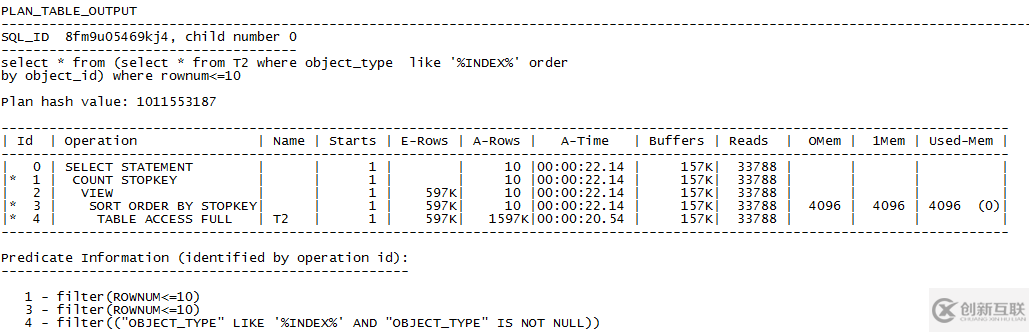
執(zhí)行時(shí)間“Elapsed: 00:00:08.75”,接近9s,從執(zhí)行計(jì)劃中看到,先是全表掃描過(guò)濾出了1597K條(1597K約163萬(wàn)條)記錄,然后作了個(gè)排序,返回object_id最小的10條記錄。
這樣的執(zhí)行效率在生產(chǎn)系統(tǒng)中是不能接受的,但是在like列上建索引效果可能并不好,本著敬業(yè)的精神,還是試一下吧。在僅有的兩個(gè)條件 object_type和object_id上建一個(gè)復(fù)合索引I_T2_ORDER2,并
加入hint提示,結(jié)果如下: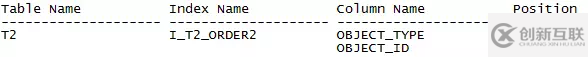
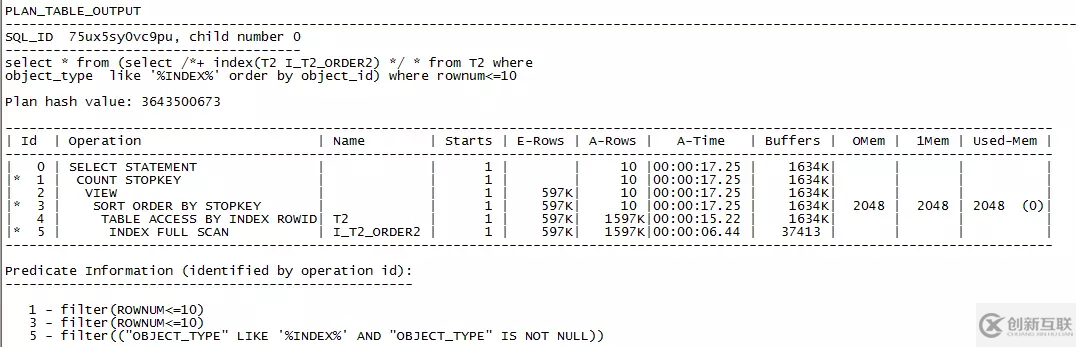
執(zhí)行時(shí)間“Elapsed: 00:00:17.25”,比剛才9秒還多花了8秒。從執(zhí)行計(jì)劃中可以看到,先是在索引I_T2_ORDER2中定位到1597K條記錄,然后回表取得1597K記錄的結(jié)果集,再排序取到object_id最小的10條記錄。與上一個(gè)執(zhí)行計(jì)劃相比,反而增加了一個(gè)讀索引的步驟,所以系統(tǒng)資源消耗更多,執(zhí)行時(shí)間也更長(zhǎng),而且雖然order by字段加入到索引中,并沒(méi)有省去排序的步驟。在這里這個(gè)索引建的就有點(diǎn)虧了。
“理想很豐滿(mǎn),現(xiàn)實(shí)很骨感”,看來(lái)SQL變得復(fù)雜以后,order by字段在索引里面果然不靈了,這招不好使。不要著急,咱們分析一下,為什么不好使了。大家都知道索引是樹(shù)狀結(jié)構(gòu),現(xiàn)在I_T2_ORDER2索引中有兩個(gè)字段,這個(gè)索引結(jié)構(gòu)大概是這個(gè)樣子的,如下圖。
大家可以看到,對(duì)應(yīng)INDEX節(jié)點(diǎn)下面的object_id“3,9,13”是有序的, INDEX PARTITION節(jié)點(diǎn)也類(lèi)似。但是把INDEX節(jié)點(diǎn)和INDEX PARTITION節(jié)點(diǎn)對(duì)應(yīng)的object_id放到一起,“3,9,13…2,15,17”,就變得無(wú)序了,所以?xún)?yōu)化器雖然使用了索引,但不得不再做一遍排序,order by索引的功效并沒(méi)有發(fā)揮出來(lái)。
看到這里是不是有點(diǎn)灰心了,這條語(yǔ)句沒(méi)法優(yōu)化了。看下本文的標(biāo)題,換個(gè)角度想一下,說(shuō)不定這條語(yǔ)句還有救。與測(cè)試表T1一樣,在object_id上建一個(gè)索引I_T2_ORDER3試一下。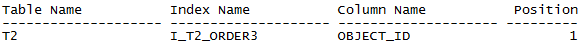
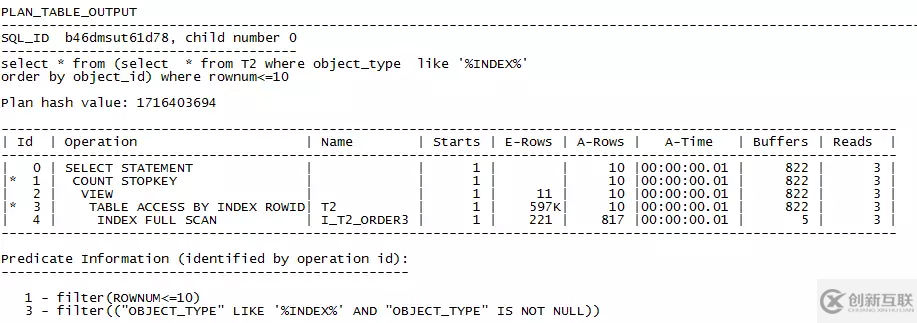
執(zhí)行時(shí)間從17s,直接變?yōu)椤癊lapsed: 00:00:00.01”,從執(zhí)行計(jì)劃可以看到,優(yōu)化器通過(guò)索引過(guò)濾了817條記錄后得到了想要的10條結(jié)果,之后回表取得結(jié)果返回。與上面的執(zhí)行計(jì)劃相比,時(shí)間消耗和資源消耗都大大減少。
這里我們簡(jiǎn)單分析一下,索引I_T2_ORDER3是按照object_id有序排列的,當(dāng)優(yōu)化器按序處理到817條記錄時(shí),就已經(jīng)得到了想要的object_type類(lèi)似INDEX,object_id最小的10條記錄,然后回表取到結(jié)果并返回,省去了全表掃描以及排序的消耗,所以效率大大提升。索引結(jié)構(gòu)如下圖。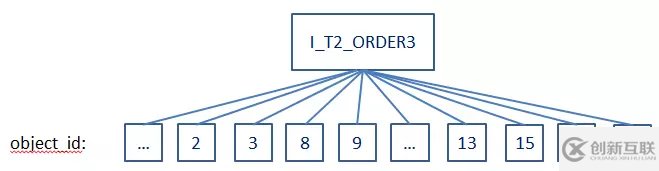
執(zhí)行時(shí)間和系統(tǒng)消耗,都大大減少,那么到這里我們是不是可以交差了。再看一下我們文章的開(kāi)頭,“對(duì)于SQL調(diào)優(yōu),要調(diào)就調(diào)到極致”, “對(duì)于頻繁執(zhí)行的單條SQL性能的提升,對(duì)整體數(shù)據(jù)庫(kù)的性能提升都有很大的意義”。我們?cè)傧胍幌逻€可不可以更優(yōu)。小編在這里又建了一個(gè)索引I_T2_ORDER4,再執(zhí)行這條查詢(xún)語(yǔ)句。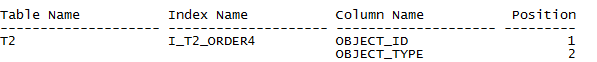
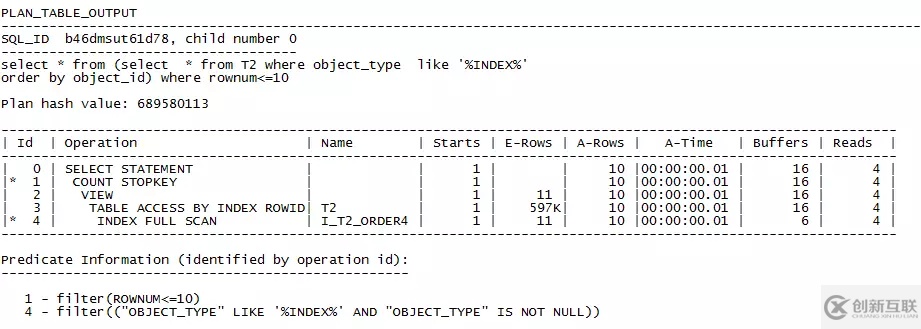
執(zhí)行時(shí)間“Elapsed: 00:00:00.01”,從執(zhí)行計(jì)劃中可以看到,優(yōu)化器通過(guò)索引直接定位到了想要的10條記錄,回表取得10條記錄并返回。最終結(jié)果只有10條記錄,優(yōu)化器也只處理了10條記錄,幾乎沒(méi)有任何的資源浪費(fèi)。I_T2_ORDER4索引的結(jié)構(gòu)圖如下,可以看到,過(guò)濾條件已經(jīng)在索引中存儲(chǔ)了,所以?xún)?yōu)化器可以在索引中直接定位到最終的10條記錄。
到這里,從建索引的角度出發(fā),小編認(rèn)為這條SQL的優(yōu)化可以交差了。
Part 3
最后小編想說(shuō)的是,遇到類(lèi)似order by字段是否加入索引的問(wèn)題,或者其他一些大家猶豫的問(wèn)題,可以大膽的嘗試,并打開(kāi)思路,從不同的角度考慮,多做測(cè)試,不要錯(cuò)過(guò)任何一個(gè)提升性能的機(jī)會(huì)。
對(duì)于order by字段加入索引本身這個(gè)問(wèn)題,如果最終的結(jié)果集是以order by字段為條件篩選的,將order by字段加入索引,并放在索引中正確的位置,會(huì)有明顯的性能提升。不過(guò)這里要注意小編前面提到的那個(gè)坑,order by字段需要是非空的屬性,否則會(huì)無(wú)效。
文章屬于轉(zhuǎn)載文章
本文名稱(chēng):一個(gè)容易被忽略的SQL調(diào)優(yōu)技巧---orderby字段到底要不要加入索引
URL分享:http://m.newbst.com/article18/jechdp.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供、用戶(hù)體驗(yàn)、網(wǎng)站內(nèi)鏈、軟件開(kāi)發(fā)、網(wǎng)站改版、網(wǎng)站設(shè)計(jì)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶(hù)投稿、用戶(hù)轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話(huà):028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)

- 外貿(mào)網(wǎng)站建設(shè)中必須掌握的幾點(diǎn) 2021-12-15
- 關(guān)于外貿(mào)網(wǎng)站建設(shè)怎樣打造優(yōu)質(zhì)外貿(mào)網(wǎng)站 2013-11-17
- 公司的外貿(mào)網(wǎng)站建設(shè)應(yīng)考慮什么因素 2014-10-31
- 給一些外貿(mào)網(wǎng)站建設(shè)經(jīng)驗(yàn)和技巧,對(duì)網(wǎng)站建設(shè)很有幫助! 2022-11-11
- 外貿(mào)網(wǎng)站建設(shè)怎么做好?做對(duì)了以下幾點(diǎn),網(wǎng)站瀏覽量翻倍 2016-03-29
- 成都外貿(mào)網(wǎng)站建設(shè)谷歌與您分享同一廣告組中的類(lèi)似關(guān)鍵字 2016-03-20
- 外貿(mào)網(wǎng)站建設(shè)要考慮的因素 2021-04-14
- 外貿(mào)網(wǎng)站建設(shè)有哪些功能? 2022-06-11
- 從以下幾方面考慮外貿(mào)網(wǎng)站建設(shè) 2022-11-20
- 外貿(mào)網(wǎng)站建設(shè)步驟,怎么制作更好優(yōu)化 2015-02-07
- 外貿(mào)網(wǎng)站建設(shè),成都哪家公司做外貿(mào)網(wǎng)站 2016-03-13
- 外貿(mào)網(wǎng)站建設(shè)報(bào)價(jià)主要有哪些方面英雄? 2016-03-04