剩余內存無法滿足申請時,系統會怎么做?-創新互聯
- 前言
- 內存的分配機制
- 回收可回收內存的類型
- 如何在保證系統性能前提下回收內存
- 可回收類型角度: 調整文件頁回收傾向
- 回收的方式角度: 盡早觸發kswapd內核線程
- 從計算機CPU架構角度: 采用NUMA
- 如何保護進程不被OOM殺掉
- 總結

當我們向操作系統申請內存時候,是否有想過一個問題:如果當前系統物理內存不足以支撐我們所需要的空間容量,操作系統會進行哪些的相關處理來保證滿足我們的要求?
答案是涉及接下來我們要講解的幾個方面
內存的分配機制, 回收可回收內存, 如何在保證性能的其拉提下滿足要求,以及如何保證不被OOM機制處死
內存的分配機制現代操作系統大部分都是使用虛擬內存的頁或者段頁式內存管理機制,當我們使用malloc等內存申請函數調用時候,所分配到的空間實際是虛擬內存,并不會分配到物理內存,當程序下次進行讀取該內存時,CPU就會去訪問該虛擬內存,然后發現其并沒有和物理內存進行映射產生關聯,CPU就會發生缺頁中斷,然后進程從用戶態轉移到內核態,交給操作系統執行PAGE_Fault(缺頁中斷處理函數);
此時PAGE_FAULT會檢查當前空余物理內存是否足夠,若足夠,則進行建立和物理內存的映射關系,若不足,則通過操作系統提供的3種常見內存回收機制進行回收內存;
3種常見內存回收機制:
后臺 回收機制(異步,不阻塞)
喚醒
kswapd內核線程來回收內存,此過程異步進行,不會阻塞進程的執行.直接 回收機制(同步,阻塞)
當后臺異步回收機制跟不上進程內存申請讀寫的速度,就開始直接回收機制,此過程同步進行,會阻塞進程的執行.
OOM(out of memory)
當直接回收機制都無法滿足內存申請要求,則執行
OOM Killer機制,它會根據算法選擇一個占用物理內存較高的進程,然后將其殺死以釋放內存資源,如果依然不足,OOM Killer將會繼續殺死占用物理內存更高的進程,直到釋放足夠的內存為止.
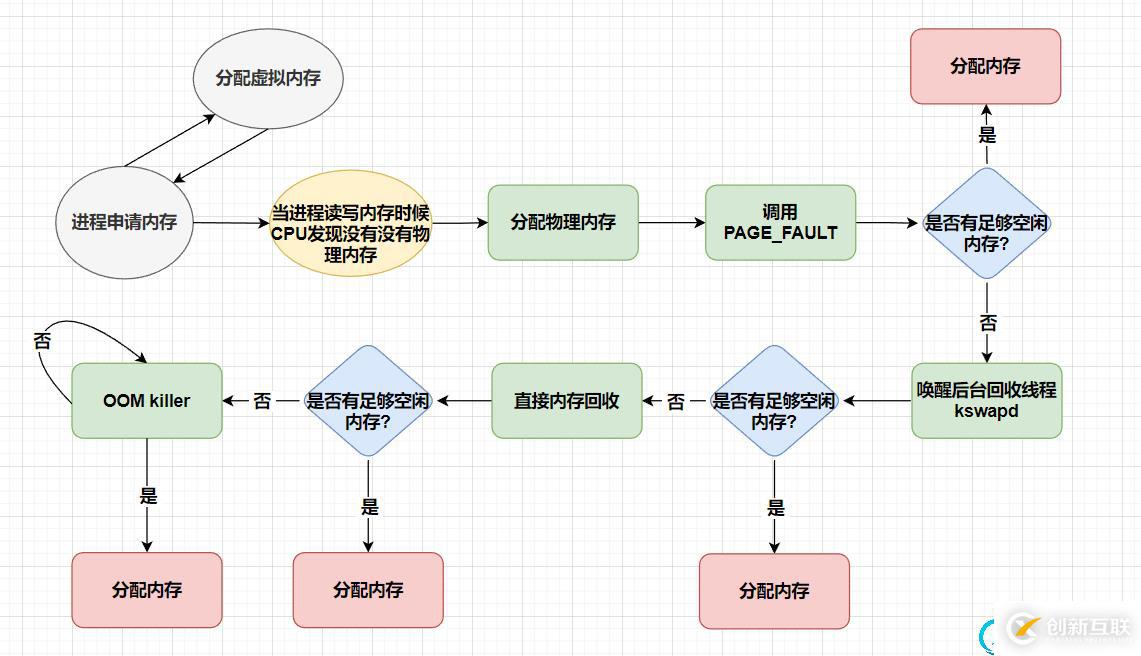
通過上面的內存分配流程圖,我們可以知道當物理內存不足以支撐需求的時候,會進行執行相關的內存回收機制,但是到底回收的是哪部分內存呢?
主要分為兩類
文件頁(file-backed pages) 內存:進程虛擬地址空間中的代碼段,以及映射的文件一般稱為文件頁
大部分文件頁,都可以直接釋放內存,當以后有需要再從磁盤讀取.而那些被修改過且還未寫入磁盤的數據(臟頁),就得先寫入磁盤才能進行內存釋放。所以,回收干凈頁的方式是直接釋放內存,回收臟頁的方式是先寫回磁盤后再釋放內存
匿名頁(anonymous pages) 內存:進程虛擬地址空間的堆,棧,數據段一般稱為匿名頁
這部分內存一般是應用程序臨時產生的,所以也不能直接釋放內存,它們回收的方式是通過 Linux 的 Swap 機制,Swap 會把不常訪問的內存先寫到磁盤中,然后釋放這些內存,給其他更需要的進程使用。再次訪問這些內存時,重新從磁盤讀入內存就可以了
更多關于文件頁和匿名頁介紹請看這里
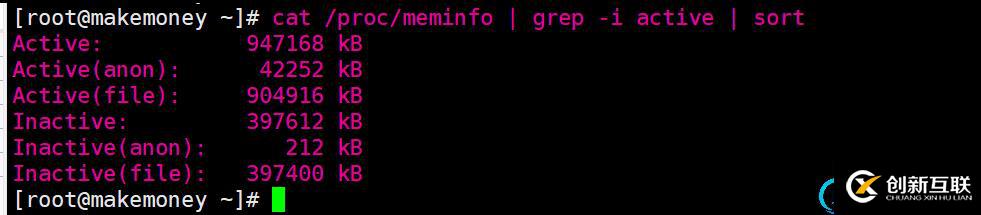
文件頁和匿名頁的回收都是基于LRU(Least Rencently Used)算法,也就是回收最近最少使用的內存。該算法維護著 active 和 inactive 兩個雙向鏈表:
- active_list 活躍內存頁鏈表,存放最近被訪問過(活躍)的內存頁;
- inactive_list 不活躍內存頁鏈表,存放最近很少被訪問(非活躍)的內存頁;
越接近鏈表尾部,就表示內存頁越不常訪問。因此,在回收內存時,系統就可以根據活躍程度,優先回收不活躍的內存。
其中在活躍頁和非活躍頁內部,又分對文件頁(file)和匿名頁(anonymous)進行了分類,可以使用linux shell命令cat /proc/meminfo | grep -i active | sort進行查看:
從上面兩個小節可以看出,以回收方式的角度看待,直接回收會阻塞進程;以可回收內存的類型角度看,臟頁和匿名頁回收會引起磁盤IO;
也就是說無論怎么樣,只要回收內存,就很容易發生IO事件,如果頻繁,就會引起系統整體性能降低,即宏觀感受到的就是系統卡頓;
那么回收內存時候,怎么可以保證性能呢?,一般通過以下三個角度看待:
可回收類型角度: 調整文件頁回收傾向文件頁主要分為干凈頁和臟頁,其中干凈頁的回收不需要發生磁盤IO,因此文件頁的效率相對匿名頁來說,回收效率更高,我們可以提高系統回收文件頁的概率(或者說傾向)高于匿名頁;
linux系統給我們提供了一個選項來進行調整
/proc/sys/vm/swappinessswappiness 的范圍是 0-100,數值越大,越積極使用 Swap,也就是更傾向于回收匿名頁;數值越小,越消極使用 Swap,也就是更傾向于回收文件頁。
所以為了效率,一般可以將swappiness的值設為0,這樣當系統回收內存時候,就更傾向于去回收文件頁(注意哦,說的是傾向,不是說就一定回收文件頁)
回收的方式角度: 盡早觸發kswapd內核線程后臺回收機制通過喚醒kswapd線程進行異步回收內存,并不會影響系統性能,因此可以通過盡早觸發kswapd的形式
但是觸發kswapd的條件是什么呢?
內核定義了三個內存閾值(watermark,也稱為水位線),用來衡量當前剩余內存是否充裕或者緊張,分別是:
頁高閾值(pages_high);
頁低閾值(pages_low);
頁最小閾值(pages_min);
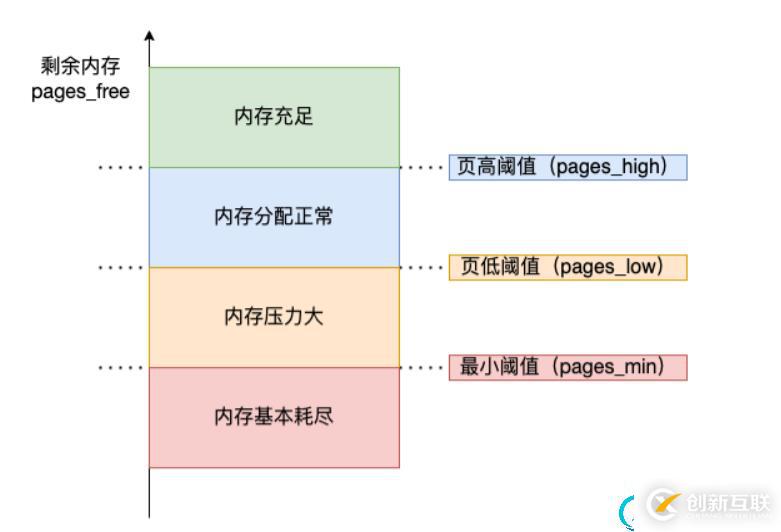
kswapd 會定期掃描內存的使用情況,根據剩余內存(pages_free)的情況來進行內存回收的工作。
- 圖中綠色部分:如果剩余內存(pages_free)大于 頁高閾值(pages_high),說明剩余內存是充足的;
- 圖中藍色部分:如果剩余內存(pages_free)在頁高閾值(pages_high)和頁低閾值(pages_low)之間,說明內存有一定壓力,但還可以滿足應用程序申請內存的請求;
- 圖中橙色部分:如果剩余內存(pages_free)在頁低閾值(pages_low)和頁最小閾值(pages_min)之間,說明內存壓力比較大,剩余內存不多了。這時 kswapd0線程就會執行內存回收,直到剩余內存大于高閾值(pages_high)為止。雖然會觸發內存回收,但是不會阻塞應用程序,因為兩者關系是異步的。
- 圖中紅色部分:如果剩余內存(pages_free)小于頁最小閾值(pages_min),說明用戶可用內存都耗盡了,此時就會觸發直接內存回收,這時應用程序就會被阻塞,因為兩者關系是同步的。
也就是說,觸發kswapd線程的條件就是pages_min< 剩余內存< pages_low
知道了這個條件后,我們就可以設置pages_min,pages_low和pages_heigh的值,進行調整觸發kswapd的條件難易了
系統給我們提供了選項
/proc/sys/vm/min_free_kbytes而它們三者之間的關系是:
pages_min = min_free_kbytes
pages_low = pages_min*5/4
pages_high = pages_min*3/2當設置好我們想要的參數以后,可以通過sar -B 1命令查看系統直接回收和后臺回收的指標變化了

- pgscank/s : kswapd(后臺回收線程) 每秒掃描的 page 個數。
- pgscand/s: 應用程序在內存申請過程中每秒直接掃描的 page 個數。
- pgsteal/s: 掃描的 page 中每秒被回收的個數(pgscank+pgscand)。
倘若在該指標變化中,發現pgscand/s的值很大,就可能是系統采用了直接回收內存的方式,因此我們可以繼續采用調整min_free_bytes的值大小方式進行盡早觸發kswapd內核線程
從計算機CPU架構角度: 采用NUMA什么是UMA結構?
每個 CPU 地位平等,它們共享相同的物理資源,包括總線、內存、IO、操作系統等,每個 CPU 訪問內存所用時間都是相同的,因此,這種系統被稱為一致存儲訪問結構(UMA,Uniform Memory Access)。
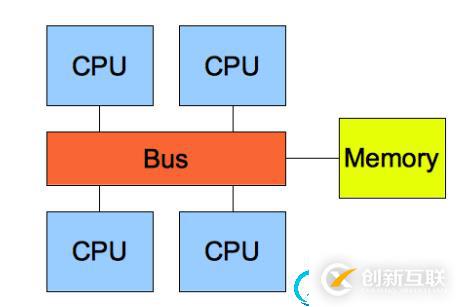
而隨著 CPU 處理器核數的增多,多個 CPU 都通過一個總線訪問內存,這樣總線的帶寬壓力會越來越大,同時每個 CPU 可用帶寬會減少,為了解決此問題,便提出了NUMA結構,即非一致存儲訪問結構,NUMA結構將每個 CPU 進行了分組,每一組 CPU 用 Node 來表示,一個 Node 可能包含多個 CPU ,每個 Node 有自己獨立的資源,包括內存、IO 等,每個 Node 之間可以通過互聯模塊總線(QPI)進行通信,所以,也就意味著每個 Node 上的 CPU 都可以訪問到整個系統中的所有內存。但是,訪問遠端 Node 的內存比訪問本地內存要耗時很多。
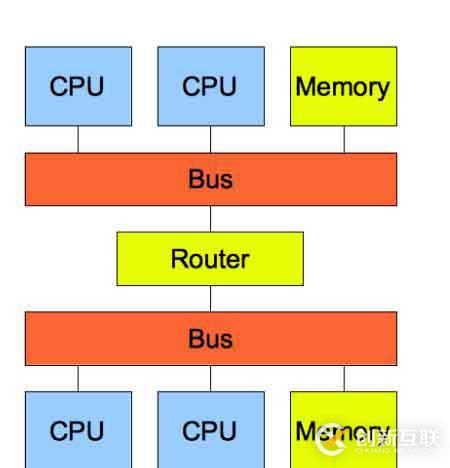
在 NUMA 架構下,當某個 Node 內存不足時,系統可以從其他 Node 尋找空閑內存,也可以從本地內存中回收內存。
具體選哪種模式,可以通過 /proc/sys/vm/zone_reclaim_mode 來控制。它支持以下幾個選項:
- 0 (默認值):在回收本地內存之前,在其他 Node 尋找空閑內存;
- 1:只回收本地內存;
- 2:只回收本地內存,在本地回收內存時,可以將文件頁中的臟頁寫回硬盤,以回收內存。
- 4:只回收本地內存,在本地回收內存時,可以用 swap 方式回收內存。
在使用 NUMA 架構的服務器,如果系統出現還有一半內存的時候,卻發現系統頻繁觸發「直接內存回收」,導致了影響了系統性能,那么大概率是因為 zone_reclaim_mode 沒有設置為 0 ,導致當本地內存不足的時候,只選擇回收本地內存的方式,而不去使用其他 Node 的空閑內存。
雖然說訪問遠端 Node 的內存比訪問本地內存要耗時很多,但是相比內存回收的危害而言,訪問遠端 Node 的內存帶來的性能影響還是比較小的。因此,zone_reclaim_mode 一般建議設置為 0
如何保護進程不被OOM殺掉在系統空閑內存不足的情況,進程申請了一個很大的內存,如果直接內存回收都無法回收出足夠大的空閑內存,那么就會觸發 OOM 機制,內核就會根據算法選擇一個進程殺掉。
Linux 到底是根據什么標準來選擇被殺的進程呢?這就要提到一個在 Linux 內核里有一個oom_badness()函數,它會把系統中可以被殺掉的進程掃描一遍,并對每個進程打分,得分最高的進程就會被首先殺掉。
進程得分的結果受下面這兩個方面影響:
- 第一,進程已經使用的物理內存頁面數。
- 第二,每個進程的 OOM 校準值 oom_score_adj。它是可以通過
/proc/[pid]/oom_score_adj來配置的。我們可以在設置 -1000 到 1000 之間的任意一個數值,調整進程被 OOM Kill 的幾率。
函數 oom_badness() 里的最終計算方法是這樣的:
// points 代表打分的結果
// process_pages 代表進程已經使用的物理內存頁面數
// oom_score_adj 代表 OOM 校準值
// totalpages 代表系統總的可用頁面數
points = process_pages + oom_score_adj*totalpages/1000用「系統總的可用頁面數」乘以 「OOM 校準值 oom_score_adj」再除以 1000,最后再加上進程已經使用的物理頁面數,計算出來的值越大,那么這個進程被 OOM Kill 的幾率也就越大。
每個進程的 oom_score_adj 默認值都為 0,所以最終得分跟進程自身消耗的內存有關,消耗的內存越大越容易被殺掉。我們可以通過調整 oom_score_adj 的數值,來改成進程的得分結果:
- 如果你不想某個進程被首先殺掉,那你可以調整該進程的 oom_score_adj,從而改變這個進程的得分結果,降低該進程被 OOM 殺死的概率。
- 如果你想某個進程無論如何都不能被殺掉,那你可以將 oom_score_adj 配置為 -1000。
我們最好將一些很重要的系統服務的 oom_score_adj 配置為 -1000,比如 sshd,因為這些系統服務一旦被殺掉,我們就很難再登陸進系統了。
但是,不建議將我們自己的業務程序的 oom_score_adj 設置為 -1000,因為業務程序一旦發生了內存泄漏,而它又不能被殺掉,這就會導致隨著它的內存開銷變大,OOM killer 不停地被喚醒,從而把其他進程一個個給殺掉。
總結內核在給應用程序分配物理內存的時候,如果空閑物理內存不夠,那么就會進行內存回收的工作,主要有兩種方式:
- 后臺內存回收:異步
- 直接內存回收:同步
而可以回收的類型也有兩種:
- 文件頁
- 匿名頁
針對回收內存導致的性能影響,常見的解決方式。
- 調整文件頁和匿名頁的回收傾向: 設置 /proc/sys/vm/swappiness 的值
- 調整 kswapd 內核線程異步回收內存的時機: 設置 /proc/sys/vm/min_free_kbytes的值
- 調整 NUMA 架構下內存回收策略: 設置 /proc/sys/vm/zone_reclaim_mod的值
當這三個性能都不能完成目標內存的申請時,就會采用OOM機制,殺掉一些根據系統評分出來的最高得分的進程,直到滿足申請要求為止;
你是否還在尋找穩定的海外服務器提供商?創新互聯www.cdcxhl.cn海外機房具備T級流量清洗系統配攻擊溯源,準確流量調度確保服務器高可用性,企業級服務器適合批量采購,新人活動首月15元起,快前往官網查看詳情吧
文章名稱:剩余內存無法滿足申請時,系統會怎么做?-創新互聯
本文網址:http://m.newbst.com/article26/dcgjcg.html
成都網站建設公司_創新互聯,為您提供網站策劃、網站營銷、軟件開發、網站收錄、定制開發、全網營銷推廣
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 企業網絡營銷需要高營業額的定制網站 2023-02-06
- 定制網站開發要怎么做才能吸引蜘蛛爬取 2023-03-25
- 企業做定制網站建設的優點是什么 2021-08-21
- 在廣州做定制網站建設需要準備多少錢? 2022-12-23
- 創新互聯定制網站的特點 2022-06-10
- 企業定制網站究竟有什么優勢 2021-05-03
- 定制網站就是高端?在本蒙面前都顯得遜色很多! 2022-08-05
- 高端定制網站建設開發的要素是什么? 2022-05-15
- 成都網絡公司定制網站有什么優勢 2022-05-30
- 模板網站pk定制網站,網站與seo的那些事 2020-08-12
- 成都網站建設之用戶為什么要選定制網站? 2016-10-16
- 定制網站建設有什么好處 2015-04-28