AI如何在工業(yè)場景中落地-創(chuàng)新互聯(lián)
本文對人工智能技術(shù)的原理、技術(shù)分類及其技術(shù)特征進行簡單的介紹;列舉一些人工智能技術(shù)在工業(yè)典型場景中的應用并對于如何搭建這樣一套工具或者平臺提出自己的一些建議。
成都創(chuàng)新互聯(lián)-專業(yè)網(wǎng)站定制、快速模板網(wǎng)站建設(shè)、高性價比荷塘網(wǎng)站開發(fā)、企業(yè)建站全套包干低至880元,成熟完善的模板庫,直接使用。一站式荷塘網(wǎng)站制作公司更省心,省錢,快速模板網(wǎng)站建設(shè)找我們,業(yè)務(wù)覆蓋荷塘地區(qū)。費用合理售后完善,十多年實體公司更值得信賴。

2016年 AlphaGo 橫空出世,人工智能、機器學習技術(shù)名噪一時。
隨著時間的發(fā)展,人工智能在工程應用上愈發(fā)成熟,車牌自動識別、智能客服機器人、廣告推薦等一系列的應用在工程和商業(yè)上均取得成功。
而在工業(yè)領(lǐng)域,人工智能也沒有停下發(fā)展的步伐,預測性維護、質(zhì)量控制、智能化排產(chǎn)等領(lǐng)域也一直在探索工程落地和商業(yè)可行的進程中取得長足的進展。大量的科技巨頭和專家預測人工智能將帶來第四次革命,繼農(nóng)業(yè)革命,工業(yè)革命,信息革命后從底層改變我們的工作和生活。
作為當前最熱門的風口領(lǐng)域之一,人工智能在工業(yè)場景中的應用深度和廣度與消費領(lǐng)域相比仍有較大差距。
因為場景通用性差、投資建設(shè)成本高等原因,導致商用化上仍局限于部分高端制造的場景,無法做到像OA、ERP、CRM等系統(tǒng)同水平的普及。
對于AI+工業(yè)互聯(lián)網(wǎng)融合的產(chǎn)品探索者而言,下一步最關(guān)鍵的問題還是具體場景落地和商用化的問題。
本文是我從科普的角度,將所學習的人工智能技術(shù)以及關(guān)于在工業(yè)場景中的應用的思考進行一些總結(jié)和整理,如有不對的地方還請各路大神磚家指正。
一、認識人工智能
1. 以機器學習為例
大到經(jīng)濟的運行,小到蘋果落在“倒霉”的牛頓頭上,世界上所有事物的發(fā)展都是由客觀規(guī)律驅(qū)動的。它大概是這樣一個模型:

就蘋果砸腦袋這件事兒而言,萬有引力和牛頓力學是驅(qū)動事物發(fā)展的客觀規(guī)律,我們可以通過它精準的判斷蘋果落下來需要多少秒、砸在腦袋上有多大的動量等具體結(jié)果。
對于經(jīng)濟問題來說,這個模型就會復雜的多了。
比如現(xiàn)在受疫情影響下,我們要討論成都的房價漲跌的問題。雖然能夠馬上判斷房價會受到了包括了供需平衡等經(jīng)濟學模型等客觀規(guī)律的支配;但是很明顯的,即便是我們知道了疫情進展、政府投資計劃、主城5區(qū)新增戶籍人口等所有的詳細數(shù)據(jù),我們還是無法準確的判斷未來半年和一年房價究竟會上浮多少,或是下跌多少。
這里就反映出一個問題:系統(tǒng)運營的規(guī)律越是復雜,就越難以通過歸納和推導的手段總結(jié)出客觀存在的規(guī)律。
機器學習技術(shù)使得計算機可以從海量的案例中通過訓練歸納總結(jié)出其內(nèi)在規(guī)律。
在創(chuàng)新工場CEO李開復著的《人工智能》一書中,對機器學習有一個定義:
機器學習……是一種用數(shù)學模型對真實世界中的特定問題進行建模,以解決該領(lǐng)域內(nèi)相似問題的過程。這樣的技術(shù)特征使得其在解決很多我們在生活、生產(chǎn)中,用傳統(tǒng)的方法難以解決或解決成本很高問題。
2. 人工智能的分類
進入九十年代,以概率統(tǒng)計建模、學習和計算為主的算法潮流開始占據(jù)主流。與此同時,人工智能的研究也開始逐漸分化為幾個主要的學科:
- 計算機視覺:讓計算機看懂世界;
- 自然語言理解和交流(包括語音識別,合成,包括對話):讓計算機聽懂世界并和世界交流;
- 機器學習 (各種統(tǒng)計的建模,分析工具和計算的方法),像時下流行的深度學習和AlphaGo涉及的增強學習(Re-enforcement Learning)就都是這個方向的分支;
- 認知和推理 (包含各種物理和社會常識),讓計算機學會思考;
- 機器人學:包括機械,控制,設(shè)計,運動規(guī)劃,任務(wù)規(guī)劃等等;
- 博弈與倫理 (主要研究多代理人的交互,對抗與合作,機器人與社會融合等議題)。
3. 人工智能的要素
人工智能要解決一個具體的項目,需要至少三個關(guān)鍵要素:
- 海量的數(shù)據(jù):計算機無法理解和識別客觀世界的規(guī)律,它需要海量的數(shù)據(jù)作為樣本進行訓練:人臉識別需要計算機大量在觀看了大量的人臉照片,機器故障的識別和預測也需要讀取海量的監(jiān)控數(shù)據(jù)。
- 充足的算力:近年來人工智能再次迎來熱潮,很大程度上得益于計算機芯片技術(shù)的發(fā)展,按照Nvidia CEO黃仁勛的說法,每10年GPU性能增長1000倍,遠超摩爾定律。即便是這樣,人工智能計算的效率仍是遠低于人腦的,需要大量的芯片提供計算支撐。
- 合適的模型:機器學習有監(jiān)督學習、無監(jiān)督學習等多達幾十種算法模型,每一個模型均有大量的參數(shù)需要配置。機器判斷的準確性高度依賴于選擇正確的算法和參數(shù)的配置。
上述條件是人工智能執(zhí)行一個成功任務(wù)的基本要求。亞馬遜的Principal Scientist夏威將此比喻為:
如果把一個成功的人工智能算法比作一只善戰(zhàn)的部隊的話,數(shù)據(jù)就是糧草,計算力就是兵力,而模型則是戰(zhàn)略和戰(zhàn)#術(shù)指揮的策略;戰(zhàn)略和戰(zhàn)#術(shù)的重要性自不必說,但沒有了糧草和兵力,再好的戰(zhàn)略也只是空中樓閣。計算力可以理解為兵力,有了強大的兵力,才有了實現(xiàn)戰(zhàn)略的機動性和可能性。
4. 在工業(yè)應用中人工智能有哪些優(yōu)勢和劣勢
優(yōu)勢
- 首先是對所解決問題的兼容。機修鉗工分析設(shè)備故障,熱處理工控制工藝參數(shù),在技能經(jīng)驗上是互不相關(guān)的;而采用機器學習的方法分別解決上述兩個問題,其開發(fā)資源和技術(shù)實現(xiàn)路徑都是幾乎一樣的。
- 其次是AI是忠于客觀的。人的總結(jié)判斷往往有局限,容易忽視一些次要因素。而人工智能并不會從物理意義或者社會意義角度來解釋規(guī)律,它只對樣本和結(jié)果負責,這樣它就可以客觀反映人類通過正向分析遺漏或誤判的內(nèi)容。
劣勢
- 首先是對數(shù)據(jù)的數(shù)量和質(zhì)量高度依賴。而人類只需要簡單的幾張圖片就能夠辨識不同品種的貓,而一個機器學習系統(tǒng)要識別需要讀取上萬張圖片才能做到。
- 此外,我們在工程上獲取的數(shù)據(jù)通常是異構(gòu)的,這意味要形成機器學習可讀的數(shù)據(jù)源,需要我們投入大量的工程資源進行數(shù)據(jù)的治理,這將大幅增加成本。
- 其次是人工智能任務(wù)完成的質(zhì)量是和從業(yè)人員的技能水平高度相關(guān)。上文提到的三大要素中,除了算力外,數(shù)據(jù)、模型都是需要具體從業(yè)人員配置。然而供需不平衡導致市場上充斥著大量的算法工程師都還停留在調(diào)庫和調(diào)參的層次和水平上,夸張一點講,“參數(shù)基本靠蒙,結(jié)果基本靠試,效果基本靠吹”的情況也是存在的。
- 最后就是成本了。在人工智能熱門的當下,無論是組建數(shù)據(jù)中心的成本,還是招募算法工程師的成本都居高不下,這導致收益平衡點后移,減少商用的可能。
二、人工智能在工業(yè)應用中的場景
1. 工業(yè)場景及痛點
工業(yè)是由眾多的場景組成的,可以從行業(yè)維度(機加工、電子產(chǎn)品、化工等)、產(chǎn)品的生命周期維度(設(shè)計、制造、銷售、運維)等逐層分解。
即便是每一個細分場景,例如針對機床的維修保養(yǎng)服務(wù),也是多人參與的復雜工作,存在這個場景特有的痛點:
- 難以找到進行設(shè)備保養(yǎng)的合適時間;
- 難以判斷設(shè)備故障的原因;
- 設(shè)備故障維修的知識都在各位老鉗工的腦子里,面對無法維修的設(shè)備時,只能通過人脈和經(jīng)驗去尋找維修資源等等;
- 同樣的,在生產(chǎn)計劃制訂的場景,存在計劃排程的問題;
- 對于安全管理的場景,存在隱患識別和排查的問題。
企業(yè)是逐利的,所有的問題(包括使用體驗的問題,效率的問題,準確性的問題)最終只要影響到企業(yè)收益,都是成立的真實痛點。
現(xiàn)在上述場景基本都是人去處理的,維護保養(yǎng)周期靠工人統(tǒng)計臺時判斷,安全隱患識別也需要大量的人員到現(xiàn)場巡查,或者在監(jiān)控室目不轉(zhuǎn)睛地看著;否則就容易漏掉安全隱患。
如果排程不合理會導致資源空閑,排程耗費的時間過長,投入資源過多;安全如果出事了,小則整改,大則關(guān)停追責。
2. 場景分類
在工業(yè)場景中,既有重復性的、常識性的腦力勞動,也有優(yōu)化等復雜的腦力勞動。
按照需要解決的問題的目標不同,我們可以將工業(yè)場景AI應用分為以下幾個類別,:
- 系統(tǒng)最優(yōu)的問題:生產(chǎn)計劃排程、結(jié)構(gòu)優(yōu)化、工藝參數(shù)優(yōu)化等;
- 分類或識別的問題:安全隱患的識別、故障類型的判斷、質(zhì)量問題識別等;
- 推薦和預測的問題:機器維護的預測、態(tài)勢預測、輔助決策等;
- 知識管理的問題:知識識別和維護、客服機器人的應用等。
3. 典型場景的分析
因技術(shù)實現(xiàn)途徑類似,從每個類別中,各取一個簡要分析,其他就不展開了。
1)工藝參數(shù)優(yōu)化
從需求有效性方面來說
工藝參數(shù)優(yōu)化對于很多企業(yè)都是優(yōu)先級極高的迫切需求,特別是流程化工領(lǐng)域更甚。
舉個栗子,硝化棉等化工產(chǎn)品的生產(chǎn)工藝過程就類似于“燒菜”,加“料”(原材料)的多少,“火候”(溫度、壓力、攪拌等)的控制,對結(jié)果(均勻度、成分含量等)都可能產(chǎn)生影響,但工程上很難準確判斷各因素對結(jié)果會產(chǎn)生何種量化的影響,它本質(zhì)是一個“黑盒”系統(tǒng)。
傳統(tǒng)的做法就是不斷地試,做新產(chǎn)品要試,換批次要試,一直做到一個批次質(zhì)量損失可以接受就按這個方法投產(chǎn)了。
因此,工藝參數(shù)優(yōu)化的問題是亟需人工智能技術(shù)來解決的。
從技術(shù)可實現(xiàn)性來說
通常是大量對過去生產(chǎn)的批次進行分析,其中將投料、工藝參數(shù)數(shù)據(jù)作為自變量,質(zhì)量數(shù)據(jù)作為因變量;進行訓練,建立模型,從而找到其內(nèi)在的量化關(guān)系。
從商業(yè)價值角度來說
即便是同一個產(chǎn)品、同一種工藝,在不同的環(huán)境下,例如海南的化工企業(yè)和甘肅的化工企業(yè)所處環(huán)境溫濕度有很大差異。部分工藝都可能因為外界環(huán)境的變化而導致算法準確度降低或失效,模型需要針對每個具體的場景定制,很難復用。
同時,工藝參數(shù)優(yōu)化會明顯受到生產(chǎn)規(guī)模和批次的制約——生產(chǎn)規(guī)模越大,單批次產(chǎn)量越高,產(chǎn)品單位價值越高或者質(zhì)量損失風險越高,使用AI進行工藝優(yōu)化就越可行。
網(wǎng)上可以找到眾多的相關(guān)成功案例。
以下案例來源于中國工程院院士鄔賀銓的演講。
“臺灣中鋼公司,他們引進了IBM的Power AI解決方案,用于分析軋鋼過程中的缺陷。為了將27噸的鋼坯,軋到0.5毫米的成品,預測和分析過程中的缺陷,他們收集了過去一年7000多批次的產(chǎn)品數(shù)據(jù)。經(jīng)過數(shù)據(jù)清洗,篩選出了可能影響產(chǎn)品質(zhì)量的特征數(shù)據(jù),并且轉(zhuǎn)換成了可供機器學習使用的數(shù)據(jù)。
這些數(shù)據(jù)中,80%拿來做學習,20%拿來做檢驗。然后他們設(shè)計了4種數(shù)學模型,來看哪種模型更符合實際情況。最后他們根據(jù)模型分析一條產(chǎn)品線產(chǎn)生的2000多個數(shù)據(jù),發(fā)現(xiàn)爐內(nèi)壓力對缺陷影響大。最后中鋼公司在人力資源和鋼坯質(zhì)量方面,都得到了很好的改進,成本大幅降低。”
2)安全隱患識別
從需求的角度來說
工廠很多危險行為(如違規(guī)操作設(shè)備、爭斗打架等)是通過現(xiàn)場檢查和視頻監(jiān)控才能發(fā)現(xiàn)的,如果能通過視頻圖像識別的話,就能夠?qū)崟r發(fā)現(xiàn)隱患并處理。
從技術(shù)可實現(xiàn)性來說
其實現(xiàn)大致流程就是做算例→配算法→訓練→嵌入框架程序用于應用。嵌入框架程序有兩種,一種是嵌入硬件的嵌入式程序,一種是服務(wù)端的web程序。此外,車牌識別,人臉識別,安全隱患識別是高度依賴于場景的。
同樣的行為,角度不同、背景不同,都可能產(chǎn)生誤判,以為著需要針對場景定制。
從商業(yè)價值角度來說
受限于危險行為場景異常復雜,無法復用且需要定制,短期內(nèi)很難做到類似車牌識別系統(tǒng)的產(chǎn)品化,導致其可用場景其實非常有限的。
3)設(shè)備維護預測
從需求的角度來說
企業(yè)的設(shè)備類似于車輛,需要定期保養(yǎng),更換零部件。一般汽車廠家為了免責而規(guī)定要求五千或者一萬公里保養(yǎng)一次,而一般老司機是不按這個來的,他們會根據(jù)行駛工況選擇合適的保養(yǎng)時機。
用于生產(chǎn)的機械設(shè)備通常是按工時來保養(yǎng)的,有的企業(yè)甚至連工時都無法統(tǒng)計(上下游標準不一或缺乏手段),導致錯過保養(yǎng)時間使得設(shè)備故障頻發(fā)。如果能夠根據(jù)實際工況給出維護保養(yǎng)建議,便能有效解決這個問題。
從技術(shù)可實現(xiàn)性來說
其技術(shù)實現(xiàn)路徑大致和工藝參數(shù)優(yōu)化一樣,不同的是自變量變成了設(shè)備的檢測到工況參數(shù),因變量變成了故障統(tǒng)計數(shù)據(jù)集。
從商業(yè)價值角度來說
其面臨的問題和工藝參數(shù)優(yōu)化一樣,受到無法復用的限制,需要大量的同類型設(shè)備才能減少邊際成本。一旦成功應用,可以極大節(jié)省設(shè)備運營和維護成本。
以下案例來源于富士康:
由于銑刀在高轉(zhuǎn)速下進行不連續(xù)切削,刀具磨損迅速且難于監(jiān)測,并且刀具磨損嚴重影響加工精度與產(chǎn)品質(zhì)量。針對高速銑削刀具磨損難以在線預測,提出了一種基于深度學習的高速銑削刀具磨損預測的新方法。通過小波包變換提取銑削力信號,在不同頻段上的能量分布,作為初始特征向量。采用無監(jiān)督學習對稀疏自編碼網(wǎng)絡(luò)進行特征學習,并將單層網(wǎng)絡(luò)堆棧構(gòu)成深度神經(jīng)網(wǎng)絡(luò)。最后,利用有監(jiān)督學習對整個深度網(wǎng)絡(luò)進行微調(diào)訓練,建立銑削刀具磨損預測模型。實驗結(jié)果表明,所提出的方法對刀具磨損狀態(tài)預測準確率達到93.038%。
4)知識識別維護
從需求的角度來說
傳統(tǒng)的知識管理軟件依賴于數(shù)據(jù)庫的設(shè)計,系統(tǒng)無法識別語義,我們只能按照預設(shè)的數(shù)據(jù)結(jié)構(gòu),在一個系統(tǒng)中實現(xiàn)增刪改查操作。而知識產(chǎn)生的時間往往和錄入的時間是不一樣的,我們往往得重復錄入一次。
例如某產(chǎn)品未通過測試需要進行設(shè)計更改,其通常會走一個變更申請,由項目負責人、總工程師等人層層審批。若能夠直接就審批材料進行語義分析,直接抽象測試未通過的要素、更改的方式方法等要素,就不需要再人為錄入了。下一次遇到類似于的問題,相關(guān)工程師就可以查詢解決方案。
從技術(shù)可實現(xiàn)性來說
可以利用自然語言識別技術(shù),從業(yè)務(wù)系統(tǒng)中直接獲取大量的文本,解析出事件執(zhí)行主體、執(zhí)行對象、執(zhí)行方法、執(zhí)行結(jié)果主要要素,再各要素語義量化解析。
從商業(yè)價值角度來說
無論是企業(yè)的技術(shù)知識庫,還是服務(wù)機器人的應用,都可以減少對人員培訓和素質(zhì)水平的依賴。結(jié)合PDM、GIT等軟件,能夠構(gòu)成企業(yè)完整的知識管理體系。
三、我們要怎么樣去構(gòu)建工業(yè)的人工智能應用
重視基礎(chǔ)條件建設(shè),數(shù)據(jù)先行。
前面案例已經(jīng)分析到了,樣本數(shù)據(jù)的數(shù)量和質(zhì)量是保障人工智能任務(wù)完成的先決條件。故障預測需要大量的工況數(shù)據(jù),危險行為識別需要大量的圖像算例。
對于企業(yè)而言,需要具備自動化、數(shù)字化等基礎(chǔ)條件,
對于行業(yè)和政府而言,需要全行業(yè)或全地域企業(yè)具備基本的自動化、數(shù)字化基礎(chǔ)。消費領(lǐng)域之所以AI做得風生水起關(guān)鍵是各應用都大量埋點,獲得了大量行為數(shù)據(jù)。
明確各自定位,參與分工。工業(yè)場景之多,復雜度之深,行業(yè)壁壘之高,意味著這不是一個贏者通吃的壟斷的市場,需要構(gòu)建生態(tài)并由多方參與。
人人都搞AI的時代并不是因為人類進化都變聰明了,而是tesorflow、opencv等AI工具的誕生。對算法的高度封裝使得我們可以專注于解決業(yè)務(wù)問題,算法從深奧的數(shù)學問題變成了”調(diào)庫和調(diào)參“+業(yè)務(wù)洞察的基本操作。
下圖是tensorflow的操作頁面——前端配置頁面已經(jīng)高度成熟,算法的配置可以通過對模塊的拖拉拽就能實現(xiàn),甚至連調(diào)庫的操作都不需要。
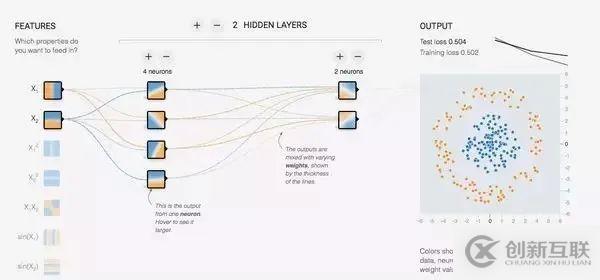
未來工業(yè)AI領(lǐng)域?qū)⒅饾u形成分工是大概率事件,參與者主要包括底層框架開發(fā)者和場景貢獻者。
框架開發(fā)者軟件、AI技術(shù)背景更強,他們搭建全行業(yè)通吃的應用框架,各行各業(yè)傳統(tǒng)的服務(wù)商基于框架構(gòu)建場景。這樣企業(yè)就能以更低的成本獲取場景,市場也各司其職,實現(xiàn)價值大化。
尊重業(yè)務(wù),深入業(yè)務(wù)。
與AI、互聯(lián)網(wǎng)日新月異的技術(shù)和商業(yè)模式的發(fā)展相比,工業(yè)的發(fā)展顯得相對緩慢和笨重;然而,工業(yè)無論是設(shè)計、工藝還是制造過程管理的知識和經(jīng)驗,都是由各個工業(yè)國家在經(jīng)過數(shù)以百年的實踐總結(jié)而來的,消費領(lǐng)域?qū)π枨蠛蜆I(yè)務(wù)的處理方式無法直接復用在工業(yè)場景中。
工業(yè)互聯(lián)網(wǎng)也好,工業(yè)AI也好,產(chǎn)品經(jīng)理需要深入理解工業(yè)場景和業(yè)務(wù)。
四、小結(jié)
人工智能技術(shù)在解決眾多工業(yè)問題場景中有獨特的優(yōu)勢,但目前工業(yè)場景與人工智能還缺乏深入融合,應用的范圍甚至還不到消費領(lǐng)域的1%。
對于工業(yè)互聯(lián)網(wǎng)從業(yè)者而言,以工程化和商用化為目標,還應深度關(guān)注業(yè)務(wù)和場景落地的問題,同時還需要探索降低場景制訂邊際成本方法。
http://blog.sina.com.cn/s/blog_cfa68e330102zvrg.html
網(wǎng)頁標題:AI如何在工業(yè)場景中落地-創(chuàng)新互聯(lián)
當前地址:http://m.newbst.com/article28/cossjp.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供手機網(wǎng)站建設(shè)、關(guān)鍵詞優(yōu)化、面包屑導航、做網(wǎng)站、網(wǎng)頁設(shè)計公司、小程序開發(fā)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容

- 自適應網(wǎng)站的優(yōu)點與缺點解析! 2022-08-14
- 自適應網(wǎng)站優(yōu)化時的優(yōu)缺點解析! 2022-10-17
- 企業(yè)建站是否應該選擇自適應網(wǎng)站設(shè)計? 2022-05-10
- 自適應網(wǎng)站的優(yōu)勢及缺點解析,建站失敗的原因解析 2022-10-24
- 自適應網(wǎng)站建設(shè)-自適應網(wǎng)站的四大注意事項 2016-11-13
- 自適應網(wǎng)站建設(shè)對SEO有哪些幫助? 2020-12-04
- 自適應網(wǎng)站建設(shè)方案是什么? 2022-11-11
- 自適應網(wǎng)站制作注意事項 2016-09-12
- 響應式網(wǎng)站和自適應網(wǎng)站的不同之處 2016-10-07
- 什么是自適應網(wǎng)站?自適應網(wǎng)站建設(shè)常見問答 2022-05-13
- 成都網(wǎng)站建設(shè):自適應網(wǎng)站有哪些優(yōu)點? 2013-08-07
- 暢響建站系統(tǒng)-自適應網(wǎng)站建設(shè)基本要點 2022-08-12