解讀電商O2O的搜索系統(tǒng)
2022-06-29 分類: 網站建設
之前的文章探討過用戶端背后系統(tǒng)的邏輯和結構情況,后續(xù)我會考慮逐步解構每個相關系統(tǒng)的情況。今天跟大家聊一聊搜索系統(tǒng),搜索系統(tǒng)在所有電商系統(tǒng)里面復雜度和難度是可以排的上前列的。關于算法方面介紹的文章很多,這里不做贅述,只解構下搜索系統(tǒng)的基本邏輯和實現(xiàn)。對于產品來說未免溝通時“露怯”,了解搜索系統(tǒng)的基本知識和結構是有必要的。

搜索系統(tǒng)的“基本介紹”
搜索系統(tǒng),顧名思義提供大數(shù)據(jù)查找篩選的系統(tǒng)功能。在電商和O2O領域作為一個主要的流量入口起到了至關重要的作用。
“基本介紹”:指標
對于搜索來說,主要的指標為準確率和召回率。我們以下圖為例解釋下什么叫做準確率和召回率。
圖中整體的部分為所有商品數(shù)據(jù)的全集,其中包括不相關和相關的內容。
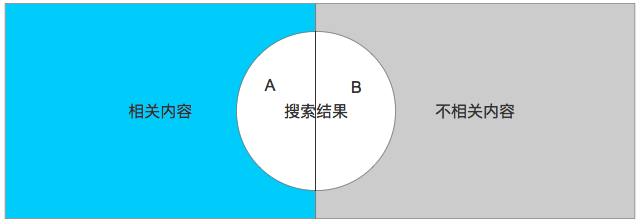
準確率:搜索結果中相關內容的比例,即圖中A的部分
召回率:搜索結果占整體內容的比例,即A+B
由此我們可以看出,最好的結果是A足夠大且B足夠小,但實際實現(xiàn)中會發(fā)現(xiàn)兩個指標是相反的(召回率越高準確率會越低)。需要通過規(guī)則來平衡這塊部分。
“基本介紹”:基礎結構
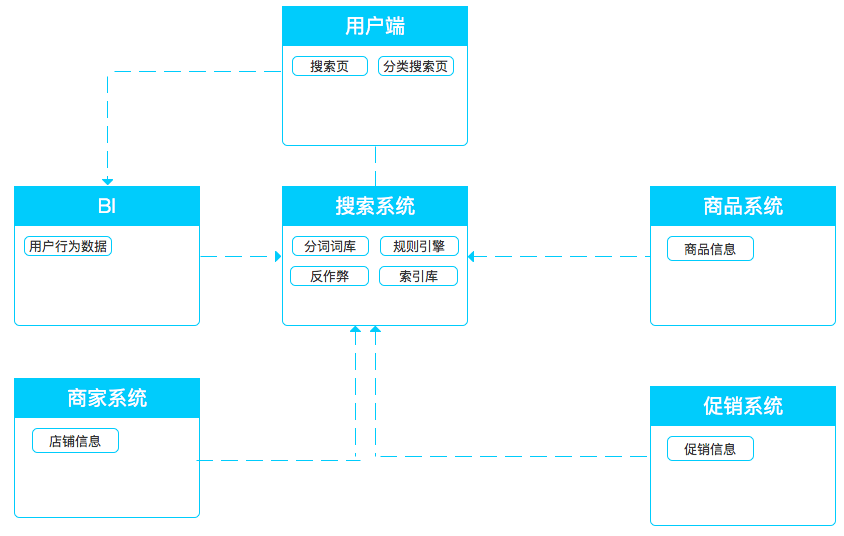
搜索系統(tǒng)主要的組成部分有幾塊:
- 切詞邏輯
- 詞庫
- 基礎信息
- 加權規(guī)則
- 排序展示邏輯
- 整體流程如下

名詞解釋:
- query:是查詢的意思,這里指用戶在搜索框輸入的內容。
- 切詞:又叫分詞,是根據(jù)詞庫/詞典將一段文本進行切分以便機器識別的過程。
- 詞庫:指用于切詞的詞庫。
- 加權:將檢索結果集按照一定的維度、規(guī)則進行打分就叫做加權。
- 索引:商品信息存儲時需要建立索引,索引作為每個商品的標識方便在大數(shù)據(jù)量的情況下快速查找篩選。
“基本介紹”:應用場景
搜索的應用一般有兩種:全文檢索和suggest。其中suggest的規(guī)則比全文檢索要簡單一些。服務上由于suggest一般支持模糊查詢的情況,所以要考慮服務上是否要獨立還是公用一套。
搜索系統(tǒng)的“工作履歷”:流程解構
切詞/詞庫
切詞,又叫分詞。用于將用戶輸入的無結構化字符變成機器可識別的詞組。市面上有很多成熟的切詞組件。切詞邏輯有很多種,根據(jù)字符、概率等,電商和O2O一般使用字符串切詞的方式處理。關于切詞的方法最基礎的有大正相匹配、大逆向匹配、雙向匹配等,具體的內容可以百度查詢。切詞工具根據(jù)詞庫中的詞典進行切分,一般開源的切詞工具都有默認的詞庫和自定義詞庫兩種情況。用戶可通過添加自定義詞庫來完善補充。
這里面需要強調的是切詞時候的過濾,尤其生鮮類非標品情況下特別需要注意。
單字詞、助詞之類的是否要過濾掉。如米、面、油等
別名情況的處理,尤其是生鮮類。比如在北京叫油菜,在上海叫上海青,在重慶叫漂兒白
檢索結果集
根據(jù)切出的詞語進行匹配,匹配到的商品信息集合為檢索結果集。結果集需要做檢索、過濾、標記三個步驟。
檢索
檢索項包括但不限于:
- 商品名稱
- 商品標題、副標題
- 商品描述
- 商品參數(shù)、規(guī)格
- 商品品牌(生鮮副食品類尤為重要,比如五得利面粉、鵬程五花肉)
- 商品品類(一級類、二級類)
- 別名關聯(lián)商品
- 促銷類型
成熟的電商系統(tǒng)不僅僅實現(xiàn)用戶的基本商品檢索,還會根據(jù)query進行意圖分析來進行query轉換。以生鮮電商舉例,當用戶搜索“豬肉”時,用戶希望獲得的不是含有豬肉詞語的商品,而是豬肉的各個部位、豬肉級別等。這時應該轉化為后臀尖、前臀尖、里脊,一級白條等詞語進行檢索,而不是匹配豬肉。意圖分析主要有兩個方面
行為模式分析
用戶畫像分類
過濾
獲取的結果集需要經過去重、過濾的處理。此部分行為可以在加權打分后進行處理,也可以安排在初選結果后處理。
同一個商品被多個詞語命中需要去重
現(xiàn)實中的電商搜索可能會根據(jù)不同的場景構建所謂的“小搜索”,如按照類目、按照品類、按照定制化場景等。所以針對不同的搜索場景可能會有單獨的過濾去重條件,也可以在構建數(shù)據(jù)的時候使用不同的庫進行處理。
O2O場景需要按照一定區(qū)域概念(城市、商圈等)進行過濾
售罄商品需要過濾
下線商品需要過濾
標記
在檢索完成后需要對數(shù)據(jù)進行標記,以便后續(xù)做加權時使用。此步也可以在做加權處理的時候同步進行。
加權
加權的目的是為了根據(jù)模型確定結果集各個商品的排序優(yōu)先級。加權的維度有很多,根據(jù)不同的場景考慮也會有所區(qū)別。
加權因子主要分為幾個維度:
相關度
商業(yè)化因素
個性化因素
人為因素
數(shù)據(jù)模型統(tǒng)計
相關度
這里指的是分詞的相關度。包括文本匹配、詞間距、是否是中心詞、品牌詞等。中心詞的概念是是否命中了核心的詞語,中心詞和品牌詞也需要有對應的詞庫進行維護更新。詞間距是計算相關性的一個維度,比如一段文本中包含清華、大學,“清華大學xxxxxxx”和“清華xxxxxxx大學”相比肯定是前者相關性更高一些。
這里面有幾點需要注意:
query被完整匹配和部分匹配的權重是不同的
單詞命中和多詞命中同一商品也需要考慮權重情況
商業(yè)化因素
考慮業(yè)務場景下需要關注的因素稱之為商業(yè)化因素。
商品庫存
是否新品(考慮新品的特殊性,也可以將此權重獨立打分)
商品銷量
是否促銷商品
銷售額
商品分類
商品品牌
CTR(廣告類的商品要考量)
所屬平臺(POP、自營)
區(qū)域(020屬性)
終端情況(手機、PC)
個性化因素
按照個人使用的情況進行個性化排序,做到所謂的“千人千面”。包括下單數(shù)據(jù)分析等。這部分同意圖分析的情況類似。
人為因素
在日常運營過程中,有很多需要做強制人為干預的事情(如人工置頂)。所以在加權的時候需要考慮此類行為。
數(shù)據(jù)模型統(tǒng)計
可以根據(jù)用戶的一些行為數(shù)據(jù)或者埋點數(shù)據(jù)分析,提供綜合排名靠前的商品或者分類做單獨加權權重。包括:
用戶點擊
用戶收藏
購買數(shù)
排序處理
根據(jù)加權的情況和一些特殊的處理,需要對最終輸出的結果做排序調整。
這里提供兩種方法供大家參考
可以按照加權打分的分值之和做排序。這樣做比較直接,但在后續(xù)調整的過程中驗證規(guī)則時容易混淆不清晰。
將不同的權重維度單獨計算,生成一個長位數(shù)的標識符,每個權重在標識符上有自己的位置。按照優(yōu)先級的順序從左到右依次排列。考慮到機器計算的易用性上,可以在加權時使用十進制,然后統(tǒng)計時轉換成二進制即可。類似下圖這樣,位數(shù)和排序可以根據(jù)具體業(yè)務場景制定。
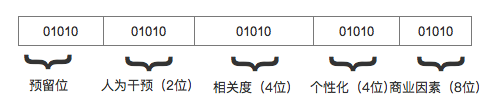
最后要說下,在算法中要考慮相同因子下的打散,比如同一個商家店鋪下的商品排序需要按照一定比例分布在不同地方,避免一次性展示過多同類商品。
如果系統(tǒng)能力富足,也可以增加單獨的反作弊模塊來處理一些惡意刷單刷榜的情況。
搜索與“大家”的關聯(lián)
搜索系統(tǒng)主要為用戶端提供搜索結果的輸出,輸入方面來自于相關的下游系統(tǒng)。
當搜索場景進一步細分時,要考慮更多數(shù)據(jù)的對接和分類。
在設計時有幾個需要注意的地方:
搜索數(shù)據(jù)比較龐大,直接使用API調用實時數(shù)據(jù)對于系統(tǒng)壓力過大,一般可采取搜索自建索引庫,定時(比如15分鐘)從相關系統(tǒng)拉取數(shù)據(jù)的方式。
基于不同的場景可以提供單獨的索引庫來實現(xiàn),避免邏輯耦合不好分離做個性化。
用戶端在調用suggest時考慮到服務壓力,建議延遲幾秒請求數(shù)據(jù)。
分詞詞庫的維護也依賴于定期從相關系統(tǒng)中獲取補充。
結語
搜索系統(tǒng)的核心是算法,從產品層面來說更多是關注業(yè)務邏輯規(guī)則以及上下游的依賴情況。本文對搜索的一些通用情況做了簡單介紹,更深入的內容還需要大家在日常過程中進一步的深挖。
網頁題目:解讀電商O2O的搜索系統(tǒng)
網址分享:http://m.newbst.com/news4/173204.html
成都網站建設公司_創(chuàng)新互聯(lián),為您提供Google、外貿網站建設、網站設計公司、企業(yè)建站、定制開發(fā)、小程序開發(fā)
聲明:本網站發(fā)布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內容
- SEO優(yōu)化網站中哪些錯誤操作會導致站點無法獲得排名? 2022-06-29
- 微信如何通過評論和留言進行引流 2022-06-29
- 「網絡營銷推廣」中小企業(yè)網絡營銷推廣的優(yōu)勢 2022-06-29
- 你為什么熱衷于在朋友圈玩點擊閱讀全文的游戲? 2022-06-29
- 優(yōu)化Mysql:3個簡單的調整 2022-06-29
- HTTP的常用消息頭 2022-06-29

- 電商APP如何做好場景營銷 2022-06-29
- 網站被百度k站的原因有哪些? 2022-06-29
- 企業(yè)手機網站應該如何建設并優(yōu)化? 2022-06-29
- 「登錄框設計」如何打造一流的用戶登錄體驗? 2022-06-29
- 我國網絡營銷的現(xiàn)狀如何?未來的發(fā)展障礙是什么? 2022-06-29
- 建設網站時選擇網站主機的四要素 2022-06-29
- 百度擴展關鍵詞的方法? 2022-06-29
- 企業(yè)推廣網站總也看不到效果?操作思路你對了嗎? 2022-06-29
- 網站推廣行業(yè)應把握市場發(fā)展趨勢 2022-06-29
- 網站打開速度慢對SEO優(yōu)化的影響,如何解決速度問題? 2022-06-29
- 建設一個好網站要注意的問題,怎么樣的方式來建設一個好的網站 2022-06-29
- SEO流量與內容營銷才能讓網站穩(wěn)健綁定潛在客戶 2022-06-29
- 百度口碑是否影響網站優(yōu)化值得關注 2022-06-29