干貨|如何利用CNN建立計算機視覺模型?
如何利用 CNNs 建立計算機視覺模型?什么是現有的數據集?訓練模型的方法有哪些?本文在嘗試理解計算機視覺的最重要的概念的過程中,為現有的一些基本問題,提供了答案。
創新互聯公司是一家專業提供科爾沁右翼中企業網站建設,專注與成都網站設計、成都網站制作、H5開發、小程序制作等業務。10年已為科爾沁右翼中眾多企業、政府機構等服務。創新互聯專業網站設計公司優惠進行中。
在機器學習中最熱門的領域之一是計算機視覺,它具有廣泛的應用前景和巨大的潛力。它的發展目的是:復制人類視覺的強大能力。但是如何通過算法來實現呢?
讓我們來看看構建計算機視覺模型中,最重要的數據集以及方法。
現有的數據集
計算機視覺算法并不神奇。 他們需要數據才能工作,并且它們只會與你輸入的數據的情況一樣。這些是收集正確數據的不同來源,具體還是要取決于任務:
ImageNet是最龐大且最著名的數據集之一,它是一個現成的數據集,包含1400萬幅圖像,使用WordNet概念手工注釋。在整個數據集中,100萬幅圖像包含邊界框注釋。

帶有對象屬性注釋的ImageNet圖像。圖片來源
另一個著名的例子是Microsoft COCO(Common Objects in Contex,常見物體圖像識別)的 DataSet,它包含了32.8萬張圖片,其中包括91種對象類型,這些對象類型很容易被識別,總共有250萬個標記實例。

來自COCO數據集的帶注釋圖像的示例
雖然沒有太多可用的數據集,但有幾個適合不同的任務,
研究人員運用了包含超過20萬名人頭像的CelebFaces Attributes數據集和超過300萬圖像的"臥室"室內場景識別數據集(15,620幅室內場景圖像);和植物圖像分析數據集(來自11個不同物種的100萬幅植物圖像)。
照片數據集,通過這些大量的數據,不斷訓練模型,使其結果不斷優化。
一個總體戰略
深度學習方法和技術已經深刻地改變了計算機視覺以及人工智能的其他領域,以至于在許多任務中,它的使用被認為是標準的。特別是,卷積神經網絡(CNN)已經超越了使用傳統計算機視覺技術的最先進的技術成果。
這四個步驟概述了使用CNN建立計算機視覺模型的一般方法:
- 創建由帶注釋的圖像組成的數據集,或使用現有的數據集。注釋可以是圖像類別(用于分類問題)、邊界框和類(用于對象檢測問題)、或者是對圖像中感興趣的每個對象進行像素級分割(對于實例分割問題)。
- 從每個圖像中提取與當前任務相關的特性。這是問題建模的關鍵點。例如,用于識別人臉的特征,基于面部標準的特征,明顯不同于用于識別旅游景點或人體器官的特征。
- 訓練一個基于特征分離的深度學習模型。訓練意味著給機器學習模型提供許多圖像,它將根據這些特征學習如何解決手頭的任務。
- 使用訓練階段沒有使用的圖像來評估模型。通過這樣做,可以測試訓練模型的準確性。
- 這個策略很基本,但可以很好地達到了目的。這種方法稱為監督機器學習,需要一個包含模型且必須學習的現象的數據集。
訓練對象檢測模型
解決對象檢測挑戰的方法有很多種。 在Paul Viola 和 Michael Jones 的論文《健壯實時對象檢測》(Robust Real-time Object Detection)中提出了普遍的方法。
論文傳送門: 「鏈接」
雖然該方法可以訓練用來檢測不同范圍的對象類,但其最初的目的是面部檢測。它是如此的快速和直接,并且它是在傻瓜相機中實現的算法,這也使得實時人臉檢測幾乎沒有處理能力。
該方法的核心特性是使用一組基于Haar特性的二進制分類器進行訓練的。這些特征表示邊和線,在掃描圖像時非常容易計算。
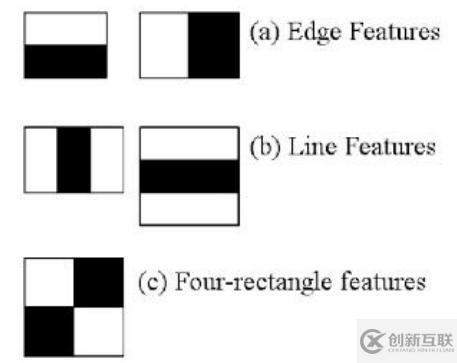
Haar features
雖然非常基本,但在特定的人臉情況下,這些特征允許捕獲重要的元素,如鼻子、嘴巴或眉毛之間的距離。它是一種監督方法,需要識別對象類型的許多正例和反例。
基于CNN的方法
深度學習已經成為機器學習中一個真正的游戲規則改變者,特別是在計算機視覺領域中,基于深度學習的方法是許多常見任務的前沿。
在提出的各種實現目標檢測的深度學習方法中,R-CNN(具有CNN特征的區域)特別容易理解。本文作者提出了三個階段的過程:
- 使用區域建議方法提取可能的對象。
- 使用CNN識別每個區域的特征。
- 利用支持向量機對每個區域進行分類。

R-CNN Architecture. 圖片來源
雖然R-CNN算法對于具體采用的區域建議方法是不可知的,但是在原著中選擇的區域建議的方法是選擇性搜索。步驟3非常重要,因為它減少了候選對象的數量,從而降低了方法的計算開銷。
這里提取的特征不如前面提到的Haar特征直觀。綜上所述,我們使用CNN從每個區域提案中提取4096維特征向量。考慮到CNN的性質,輸入必須始終具有相同的維度。這通常是CNN的弱點之一,不同的方法以不同的方式解決這個問題。對于R-CNN方法,經過訓練的CNN架構需要輸入227×227像素去固定區域。由于提議的區域大小與此不同,作者的方法只是扭曲圖像,使其符合所需的尺寸。

與CNN所需的輸入維度匹配的扭曲圖像的示例
雖然取得了很好的效果,但是訓練遇到了一些障礙,最終這種方法被其他人超越了。其中一些在文章中進行了深入的回顧——《深度學習的對象檢測:權威指南》。
https://www.toutiao.com/a6693688027820065292/
名稱欄目:干貨|如何利用CNN建立計算機視覺模型?
文章路徑:http://m.newbst.com/article40/gpjjho.html
成都網站建設公司_創新互聯,為您提供網站排名、手機網站建設、定制網站、做網站、網頁設計公司、商城網站
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 網站設計為什么要做面包屑導航? 2020-12-25
- 北京網站建設講解面包屑導航有什么作用? 2021-05-21
- 企業網站設計的面包屑導航有什么用 2021-08-22
- 網站制作面包屑導航為訪客指明方向 2022-08-12
- 解析面包屑導航對SEO有什么作用呢 2021-11-30
- 網站SEO優化之面包屑導航的簡易設置步驟 2023-04-04
- 關于營銷型網站建設中的面包屑導航 2020-07-18
- 成都網絡SEO要怎么做面包屑導航? 2023-04-07
- 網站建設中的面包屑導航有什么作用? 2016-10-01
- 面包屑導航對網站SEO優化推廣的重要性 2022-08-12
- 面包屑導航的作用和對購物體驗的提升 2016-09-30
- 淺談網站建設中面包屑導航的運用 2016-10-11