聊聊大數(shù)據(jù)Lambda架構(gòu)
2021-02-04 分類: 網(wǎng)站建設
Lambda Architecture 概念
Mathan Marz的大作Big Data: Principles and best practices of scalable real-time data systems介紹了Lambda Architecture的概念,用于在大數(shù)據(jù)架構(gòu)中,如何讓real-time與batch job更好地結(jié)合起來,以達成對大數(shù)據(jù)的實時處理。
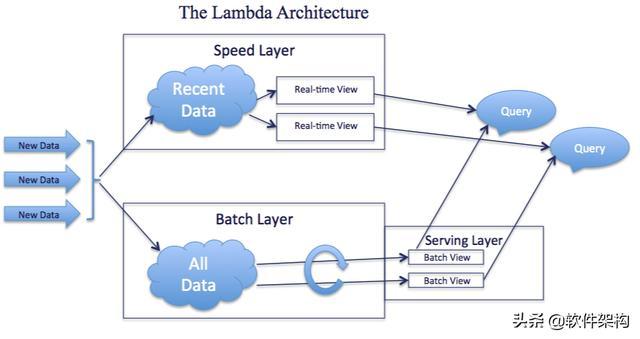
大數(shù)據(jù)平臺中包括批量計算的Batch Layer和實時計算的Speed Layer,通過在一套平臺中將批計算和流計算整合在一起。
例如使用Hadoop MapReduce、Spark進行批量數(shù)據(jù)的處理,使用Apache Storm、Spark Streaming 進行實時數(shù)據(jù)的處理。
這種架構(gòu)在一定程度上解決了不同計算類型的問題,但是帶來的問題是框架太多,會導致平臺復雜度過高、運維成功高等。
Lambda架構(gòu)的主要思想就是將大數(shù)據(jù)系統(tǒng)構(gòu)建為多個層次,如下圖所示:
我們來梳理一下他們是如何分工協(xié)助的:
- 首先new data作為整個數(shù)據(jù)系統(tǒng)的數(shù)據(jù)源頭,Batch Layer作為數(shù)據(jù)的批處理層次對原始數(shù)據(jù)進行加工與處理,并且將處理的數(shù)據(jù)結(jié)果的Batch View輸入到Serving Layer。(這里對應的是全量數(shù)據(jù))
- Speed Layer對于實時增加的數(shù)據(jù)進行處理,生成對增量數(shù)據(jù)計算結(jié)果的Real-time View。(這里對應的是增量數(shù)據(jù))
- 最終用戶查詢是通過Batch View與Real-time View相結(jié)合的形式將最終結(jié)果呈現(xiàn)出來。
基于Lambda架構(gòu),一旦數(shù)據(jù)通過Batch layer進入到Serving layer,在Real-time view中的相應結(jié)果就不再需要了。
小 結(jié)
Lambda架構(gòu)結(jié)合了實時處理與批處理的結(jié)果,很好的反饋了查詢需求,并且在速度和可靠性之間求取了平衡,具有足夠的擴展性。理想狀態(tài)下,所有的查詢都可以定位成一個函數(shù):
- Query?=?Function(Data)?
但是,若數(shù)據(jù)達到相當大的一個級別(例如PB),且還需要支持實時查詢時,就需要耗費非常龐大的資源。
而Lambda架構(gòu)將數(shù)據(jù)和計算系統(tǒng)進行細分:
- Query?=?Batch(Old_Data)?+?RealTime(New_Data)?
但是這種架構(gòu)同樣存在一些問題:需要運維兩套不同的計算系統(tǒng),并且合并查詢結(jié)果,這一定程序上帶來了復雜性的增加。
網(wǎng)頁名稱:聊聊大數(shù)據(jù)Lambda架構(gòu)
本文路徑:http://m.newbst.com/news/99044.html
成都網(wǎng)站建設公司_創(chuàng)新互聯(lián),為您提供動態(tài)網(wǎng)站、定制開發(fā)、品牌網(wǎng)站設計、搜索引擎優(yōu)化、網(wǎng)站改版、全網(wǎng)營銷推廣
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- 百度SEO怎么收費?如何推廣才有流量? 2021-02-04
- 一分鐘帶你了解建設網(wǎng)站對于企業(yè)的真正意義 2021-02-04
- 智能客服為何能夠快速滲透各行各業(yè)? 2021-02-04
- 模板建站類型有哪些?看看你適合做哪種網(wǎng)站 2021-02-04
- 跨境電商運營模式包括哪些? 2021-02-04
- 你的跨境電商平臺,如何選擇服務器? 2021-02-04
- 小程序與APP和公眾號的區(qū)別? 2021-02-04

- 想實現(xiàn)移動廣告規(guī)模變現(xiàn) 你必須了解的關(guān)鍵要素 2021-02-04
- SSL證書抵御企業(yè)網(wǎng)絡攻擊的風險 2021-02-04
- 跨境電商賣家如何打開日本電商市場 2021-02-04
- 安裝SSL安全證書對網(wǎng)站有哪些影響 2021-02-04
- 計算機網(wǎng)絡太難?了解這一篇就夠了 2021-02-04
- 微信又上線新功能!網(wǎng)友炸了 2021-02-04
- 數(shù)據(jù)安全三部曲:存儲、傳輸與使用 2021-02-04
- 域名搶注的技巧及域名到期后的幾個狀態(tài) 2021-02-04
- 電商時代 | 如何抓住年輕人的市場 2021-02-04
- 沉寂多年,無服務器爆發(fā),其硬核是什么? 2021-02-04
- 域名對企業(yè)重要不重要嗎?有什么影響 2021-02-04
- 現(xiàn)代企業(yè)為什么要開發(fā)小程序 2021-02-04