運維監控的終極秘籍,盤它!
2021-02-23 分類: 網站建設
一般來說,白盒與黑盒分別從內部和外部來監控系統的運行狀況,例如機器存活、CPU內存使用率、業務日志、JMX等監控都屬于白盒監控,而外部端口探活、HTTP探測以及端到端功能監控等則屬于黑盒監控的范疇。
下面將主要從白盒監控的采集入手,解答上面關于新系統如何添加監控的問題。
圖 1 黑盒與白盒監控
監控指標的采集
配置監控時,我們首要面對的是監控數據如何采集的問題。一般我們可以把監控指標分為兩類:基礎監控和業務監控。
基礎監控
包括CPU、內存、磁盤、端口和進程等機器、網絡的操作系統級別的信息。通常情況下,成熟的監控系統(例如開源的Prometheus、Zabbix等)均會提供基礎監控項的采集能力,這里不做過多介紹。但需要注意的一點,機器級別的基礎監控指標一般并不能代表服務的真實運行狀況,例如單臺實例的故障對一個設計合理的分布式系統來說并不會帶來嚴重后果。所以只有結合業務相關監控指標,基礎監控指標才有意義。
業務監控
業務監控指標由業務系統內部的服務產生,一般能夠真實反應業務運行狀態。設計合理的系統一般都會提供相關監控指標供監控系統采集。監控數據的采集方法一般可以分為以下幾大類:
- 日志:日志可以包含服務運行的方方面面,是重要的監控數據來源。例如,通過Nginx access日志可以統計出錯誤(5xx)、延遲(響應時間)和流量,結合已知的容量上限就可以計算出飽和度。一般除監控系統提供的日志采集插件外,如Rsyslog、Logstash、Filebeat、Flume等都是比較優秀的日志采集軟件
- JMX:多數Java開發的服務均可由JMX接口輸出監控指標。不少監控系統也有集成JMX采集插件,除此之外我們也可通過jmxtrans、jmxcmd工具進行采集
- REST:提供REST API來進行監控數據的采集,如Hadoop、ElasticSearch
- OpenMetrics:得益于Prometheus的流行,作為Prometheus的監控數據采集方案,OpenMetrics可能很快會成為未來監控的業界標準。目前絕大部分熱門開源服務均有官方或非官方的exporter可供使用
- 命令行:一些服務提供本地的命令來輸出監控指標
- 主動上報:對于采用PUSH模型的監控系統來說,服務可以采取主動上報的方式把監控指標push到監控系統,如Java服務可使用Metrics接口自定義sink輸出。另外,運維也可以使用自定義的監控插件來完成監控的采集
- 埋點:埋點是侵入式的監控數據采集方式,其優點是其可以更靈活地為我們提供業務內部的監控指標,當然缺點也很明顯:需要在代碼層面動手腳(常常需要研發支持,成本較高)
- 其它方式:以上未涵蓋的監控指標采集方式,例如Zookeeper的四字命令,MySQL的show status命令
以上列出了幾種常見的監控指標采集方法,在實際工作,如果沒有現成的監控采集插件,則需要我們自行開發采集腳本。
四個黃金指標
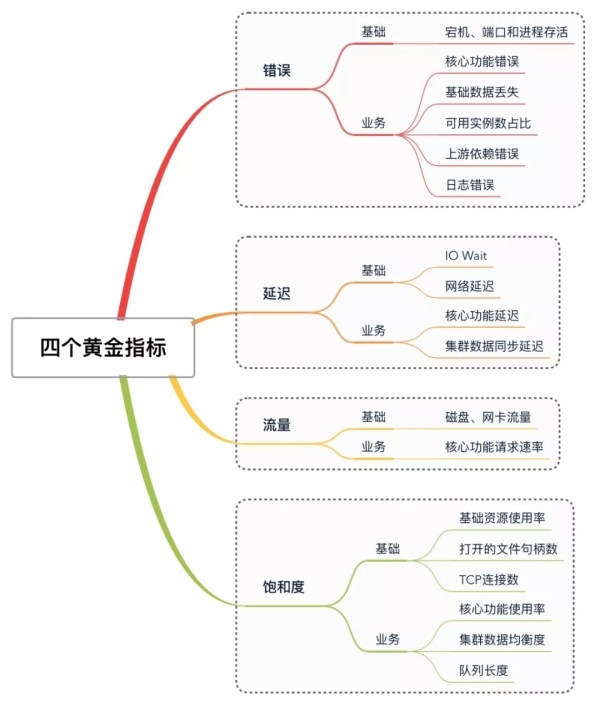
圖 2 四個黃金指標
無論業務系統如何復雜,監控指標如何眼花繚亂,但萬變不離其宗,監控的目的無非是為了解服務運行狀況、發現服務故障和幫助定位故障原因。為了達成這個目的,Google SRE總結的監控四個黃金指標對我們添加監控具有非常重要的指導意義。圖 2給出四個黃金指標所包含的主要監控指標,下面我們就這四個黃金指標分別展開說明,并給出一些監控項的采集實例。
錯誤:錯誤是指當前系統發生的錯誤請求
和錯誤率
說明:
錯誤是需要在添加監控時首要關注的指標。在添加錯誤相關監控時,我們應該關注以下幾個方面:
基礎監控:宕機、磁盤(壞盤或文件系統錯誤)、進程或端口掛掉、網絡丟包等故障
業務監控:
- 核心功能處理錯誤,每種系統都有特定的核心功能,比如HDFS的文件塊讀寫、Zookeeper對Key的讀寫和修改操作
- 基礎功能單元丟失或異常,這里的基礎功能單元是指一個系統功能上的基本單位,例如HDFS的Block、Kafka的Message,這種基礎數據的丟失一般都會對業務功能造成直接的影響
- Master故障,對于中心化的分布式系統來說,Master的健康狀況都是重中之重。例如HDFS的NameNode、Zookeeper的Leader,ElasticSearch的MasterNode
- 可用節點數,對于分布式系統來說,可用節點數也是非常重要的,比如Zookeeper、ETCD等系統需要滿足可用節點數大于不可用節點數才能保證功能的正常
注意:除白盒監控外,主要功能或接口、以及內部存在明顯邊界的功能模塊和上游依賴模塊,都應該添加黑盒端到端監控。
延遲:服務請求所需時間
說明:
服務延遲的上升不僅僅體現在用戶體驗的下降,也有可能會導致請求堆積并最終演變為整個業務系統的雪崩。以下為延遲指標的主要關注點:
- 基礎監控:IO等待、網絡延遲
- 業務監控:業務相關指標主要需要關注核心功能的響應時長。比如Zookeeper的延遲指標zk_avg_latency,ElasticSearch的索引、搜索延遲和慢查詢
注意:與錯誤指標類似,白盒延遲指標通常僅能代表系統內部延遲,建議為主要功能或接口添加黑盒監控來采集端到端的延遲指標。
流量:當前系統的流量
說明:
流量指標可以指系統層面的網絡和磁盤IO,服務層面的QpS、PV和UV等數據。流量和突增或突減都可能預示著系統可能出現問題(攻擊事件、系統故障…)。
- 基礎監控:磁盤和網卡IO
- 業務監控:核心功能流量,例如通過QpS/PV/UV等通常能夠代表Web服務的流量,而ElasticSearch的流量可用索引創建速率、搜索速率表示
飽和度:用于衡量當前服務的利用率
說明:
更為通俗的講,飽和度可以理解為服務的利用率,可以代表系統承受的壓力。所以飽和度與流量息息相關,流量的上升一般也會導致飽和度的上升。通常情況下,每種業務系統都應該有各自的飽和度指標。在很多業務系統中,消息隊列長度是一個比較重要的飽和度指標,除此之外CPU、內存、磁盤、網絡等系統資源利用率也可以作為飽和度的一種體現方式。
基礎監控:CPU、內存、磁盤和網絡利用率、內存堆棧利用率、文件句柄數、TCP連接數等
業務監控:
- 基礎功能單元使用率,大多數系統對其基礎的功能單元都有其處理能力的上限,接近或達到該上限時可能會導致服務的錯誤、延遲增大。例如HDFS的Block數量上升會導致NameNode堆內存使用率上升,Kafka的Topics和Partitions的數量、Zookeeper的node數的上升都會對系統產生壓力
- 消息隊列長度,不少系統采用消息隊列存放待處理數據,所以消息隊列長度在一定程度上可以代表系統的繁忙程度。如ElasticSearch、HDFS等都有隊列長度相關指標可供采集
總結
以上總結了常見的監控指標采集方法,以及四個黃金指標所包含的常見內容。在實際工作中,不同的監控系統的設計多種多樣,沒有統一標準,并且不同的業務系統通常也有著特定的監控采集方法和不同的黃金指標定義,具體如何采集監控指標和添加告警都需要我們針對不同系統特點靈活應對。
在前面的監控系列文章中,我們介紹了Kafka、Zookeeper、ElasticSearch、Hadoop以及電商商城平臺等一系列開源軟件和業務系統的監控實踐。但通常情況下,線上業務一般是由眾多開源或自研中間件加上層業務系統組成。而業務系統的復雜度會隨著系統變更和新業務上線而發生快速增長。不斷變化的業務環境下,新業務層出不窮。當面臨一個新系統時,監控工作應該如何開展?
本文標題:運維監控的終極秘籍,盤它!
當前地址:http://m.newbst.com/news0/102500.html
成都網站建設公司_創新互聯,為您提供網站營銷、網站收錄、云服務器、虛擬主機、小程序開發、網站策劃
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯
猜你還喜歡下面的內容
- 云計算,未來大不同 2021-02-23
- MySQL每秒570000的寫入,如何實現? 2021-02-23
- 查漏補缺:連接器在Tomcat中是如何設計的 2021-02-23
- 社交電商為何如此火爆?讀懂這四大優勢:搶占未來先機 2021-02-23
- 網站在建設時 文本該如何排版? 2021-02-23
- 網絡推廣越來越難?未來怎么做好網絡營銷? 2021-02-23
- 5G流量爆發,云計算加速,IDC明顯受益 2021-02-23

- 提升DNS安全 限制DDoS攻擊 2021-02-23
- 企業如何做好網站推廣營銷 2021-02-23
- 從4G到5G,只是網速加快了這么簡單嗎? 2021-02-23
- 企業網站為什么一定要做SEO? 2021-02-23
- 一文讀懂Kafka 2021-02-23
- 云主機選購有訣竅 創新互聯支招 2021-02-23
- 百度站長學院:死鏈提交工具注意事項 2021-02-23
- 100元買入域名,三個月后翻了近百倍 2021-02-23
- 使機器學習更容易采用的6種工具 2021-02-23
- 小程序為什么吸引巨頭 2021-02-23
- 深度解析 Flink 是如何管理好內存的? 2021-02-23
- 新建網站如何做SEO優化 2021-02-23